Hadoop Name Node
· Version : HDFS
네임노드(Namenode)는 파일 시스템의 네임스페이스를 관리한다. 네임노드는 파일 시스템 트리와 그 트리에 포함된 모든 파일과 디렉터리에 대한 메타데이터를 유지한다. 이 정보는 네임스페이스 이미지(namespace image)와 에디트 로그(edit log)라는 두 종류의 파일로 로컬 디스크에 영속적으로 저장된다. 네임노드는 파일에 속한 모든 블록이 어느 데이터노드에 있는지 파악하고 있다. 하지만 블록의 위치 정보는 시스템이 시작할 때 모든 데이터노드로 부터 받아서 재구성하기 때문에 디스크에 영속적으로 저장하지는 않는다.
네임노드는 메타데이터를 관리하기 때문에 네임노드에 장애가 발생하면 파일 시스템은 동작하지 않으며 파일 시스템의 어떠한 파일도 찾을 수 없다. 데이터 노드에 블록이 저장되어 있지만 이러한 블록 정보를 이용하여 파일을 재구성할 수 없기 때문이다. 따라서 네임노드의 2중화 및 장애복구 전략은 필수적이다. 아래 그림은 Namenode HA의 주요 컴포넌트 구성이다.
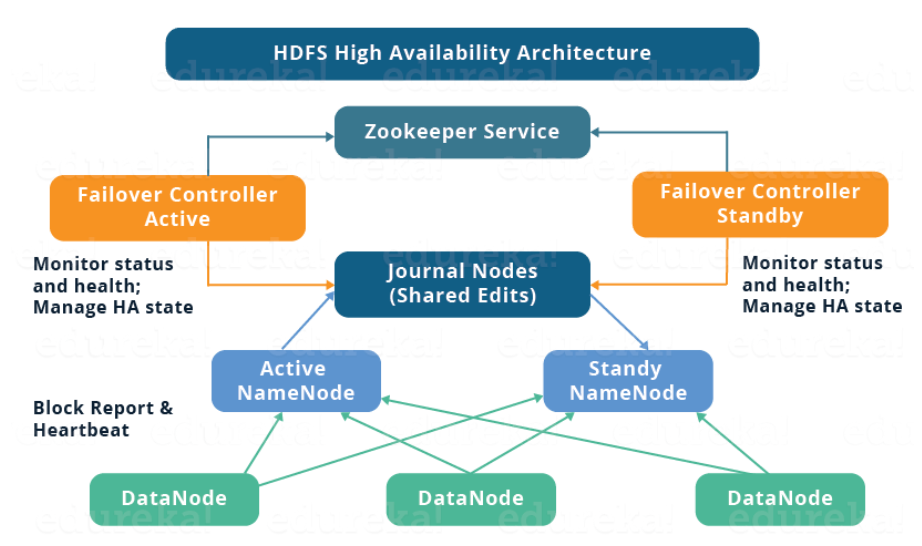
[저널노드]
· 하둡 1.0에서는 네임노드에서만 에디트 로그 저장하고, 하둡 2.0에서는 여러 서버에 에디트 로그를 복제해서 저장한다.
· 저널노드(데몬)는 에디트 로그를 자신이 실행되는 서버의 로컬디스크에 저장한다.
· 네임노드는 클라이언트가 돼서 저널노드에게 접근해 저장을 요청. 단 액티브 네임노드만 에디트로그를 저장할 권한이 있으며 스탠바이 네임노드는 조회만 요청 가능하다.
· 저널노드는 3대 이상의 서버에서 실행되어야하고 홀수 단위로만 실행가능하기 때문에, 네임노드가 저널노드의 장애에 영향을 받지 않으려면 "(전체 저널노드 설치대수/2) / +1" 만큼 노드가 필요하다. (ex : 5대에 저널 노드를 설치했으면 최소 3대 이상의 저널노드가 실행)
· 리소스를 적게 사용하기 때문에 "네임노드", "잡트래커", "리소스매니저"와 같은 데몬이 돌아가는 서버에서 함께 실행 가능하다.
[주키퍼]
· 네임노드 HA 상태 정보를 저장하는 장소이며 어떤 서버가 액티브(active) 네임노드인지 스탠바이(standby) 네임노드인지 저장한다.
· 분산시스템 코디네이터 역할을 하며 서버 간의 정보 공유한다.
· 서버 모니터링하여 새로운 노드를 추가하거나 삭제하였을때, 다른 노드들에게 알려준다.
· 주키퍼 마스터(주키퍼 앙상블에 구성된 주키퍼 한대)는 홀수 단위로 실행하며 주키퍼 클라이언트는 주키퍼 마스터가 응답을 안할 경우 다른 주키퍼 마스터 에게 요청한다. (2대중 한대가 고장나면 실행 안됨)
· 주키퍼 마스터는 동일한 주키퍼 데이터를 복제하고 있기 때문에 클라이언트로부터 조회요청이 들어오면 자신이 보관한 데이터를 이용해 응답하며 쓰기 요청은은 오로지 리더로 설정된 주키퍼 마스터에게 보내진다.
· ZNode: 주키퍼에서 저장되는 파일 하나하나를 ZNode라고 함
[ZKFC (Zookeeper Failover Controller)]
· 로컬 네임노드(자신이 위치한 네임노드)의 상태를 모니터링하며 주키퍼 세션 관리한다.
· 액티브 네임노드의 상태가 정상이면 주키퍼 마스터에 대한 세션 유지하며 액티브 네임 노드에 장애가 발생하면 자동으로 ZKFC와 주키퍼 마스터 간의 세션을 종료하고 스탠바이 네임 노드를 액티브 네임 노드로 전환하며, 기존의 액티브 네임 노드 제거한다.
[네임노드]
· 네임노드 내부에 있는 QJM(Quorum Journal Manager)이 저널노드에 에디트 로그 출력하며, 반드시 절반이상의 저널노드가 실행되고 있어야 에디트 로그를 fsimage에 반영할 수 있다. (3대중 2대는 최소 작동)
· 액티브 네임노드만 저널노드에 에디트로그 쓸수 있으며, 스탠바이 네임노드는 저널노드에서 에디트로그 조회하고 fsimage를 갱신한다.
[데이터 노드]
· 데이터노드의 블록 정보를 액티브 네임노드, 스탠바이 네임노드로 리포트 전송
네임노드 장애 복구를 위해서는 아래와 같은 절차를 사용할 수 있다.
· 네임노드 로컬 디스크와 원격의 NFS 마운트 두 곳에 동시 백업진행한다.
· 파일 시스템의 데타데이터를 지속적인 상태로 보존하기 위해 파일로 백업한다.
· 보조 네임 노드를 운영한다. 병합 작업을 수행하기 위해 보조 네임노드는 충분한 CPU와 네임노드와 비슷한 용량의 메모리가 필요하므로 별도의 물리 머신에 실행되는것이 좋다.
· 보조 네임 노드는 주 네임노드에 장애가 발생할 것을 대비해서 네임스페이스 이미지의 복제본을 보관하는 역할도 맡는다. 하지만 주 네임노드의 네임스페이스 이미지는 약간의 시간차를 두고 보노 네임 노드로 복제되기 때문에 주 네임노드에 장애가 발생하면 어느정도의 데이터 손실은불가피 하다. 일반적인 복구 방식은 NFS에 저장된 주 네임노드의 메타데이터 파일을 보조 네임노드로 복사하여 새로 병합된 네임스페이스 이미지를 만들고 그것을 새로운 주 네임노드에 복사한 다음 실행하는 것이다.
2019-11-18 / Sungwook Kang / http://sungwookkang.com
Hadoop, 하둡, HDFS, 하둡 파일 저장, NameNode, 네임노드, 보조네임노드, Secondary NameNode
'SW Engineering > Hadoop' 카테고리의 다른 글
| HBase와 Zookeeper 상호작용 관계 (0) | 2019.11.21 |
|---|---|
| NameNode and Secondary NameNode Heap Memory Size 변경 (0) | 2019.11.20 |
| HDFS 블록 (0) | 2019.11.16 |
| HDFS 파일 저장(로컬 업로드) (0) | 2019.11.14 |
| Cloudera Hadoop 6.3.0 Install (0) | 2019.11.14 |