MapReduce (맵리듀스)
· Version : Hadoop 3.0.0-cdh6.3.2,
맵리듀스는 간단한 단위 작업을 반복하여 처리할때 사용하는 프로그래밍 모델이다. 간단한 작업을 처리하는 맵(Map) 작업과 맵 작업의 결과물을 모아서 집계하는 리듀스(Reduce) 단계로 구성된다.
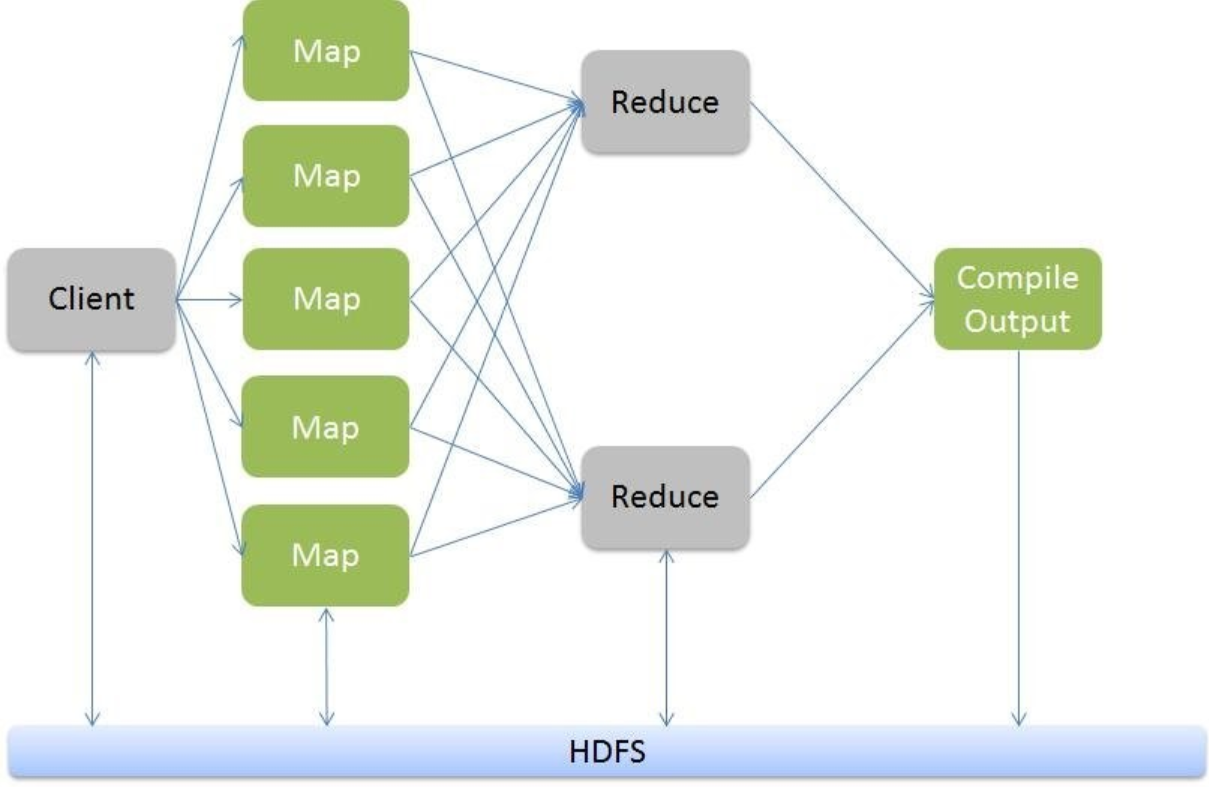
하둡에서 분산처리를 담당하는 맵 리듀스 작업은 맵과 리듀스로 나누어져 처리된다. 맵리듀스 작업은 병렬로 처리가 가능하며 여러 컴퓨터에서 동시에 작업을 처리하여 속도를 높일 수 있다. 맵리듀스가 분산, 병렬처리하기 좋은 이유는 입력 데이터에 대한 맵 함수는 동시에 독립적으로 병영 처리할 수 있는 구조이기 때문이다. 아래는 맵리듀스 처리 순서이다.

1. 분할(Splitting) : 입력한 파일 값을 라인 단위로 분할한다.
2. 매핑(Mapping) : 분할된 라인 단위 문장을 맵(Map)함수로 전달하면 맵함수는 공백을 기준으로 문자를 분리, 단어 개수를 확인한다.
3. 셔플링(Shuffling) : 메모리에 저장되어 있는 맵 함수의 출력 데이터를 파티셔닝과 정렬하여 로컬 디스크에 저장, 네트워크를 통해서 리듀서의 입력 데이터로 전달한다.
4. 리듀싱(Reducing) : 단어 목록들을 반복적으로 수행하고 합을 계산하여 표시한다.
맵리듀스의 장단점
|
단점 |
장점 |
|
· 고정된 단일 데이터 흐름 · 기본 DBMS 보다 불편한 스키마 · 단순한 스케줄링 · 상대적으로 낮은 성능 · 개발도구의 불편함 · 오픈소스 기술지원 한계 |
· 단순하고 사용이 편리 · 특정 데이터모델이나 스키마, 질의에 의존적이지 않은 높은 유연성 · 저장 구조의 독립성 · 데이터복제에 기반한 내구성과 내고장성 확보 · 높은 확장성 |
2019-12-27 / Sungwook Kang / http://sungwookkang.com
Hadoop, MapReduce, 맵리듀스, Map, Reduce
'SW Engineering > Hadoop' 카테고리의 다른 글
| Hive에서 콤마(,)로 컬럼 구분 및 쿼테이션 내부의 콤마(“, , ”) 파싱 스킵하기 (0) | 2020.01.03 |
|---|---|
| MapReduce JobTracker (0) | 2019.12.31 |
| Hive Buckets (버켓) (0) | 2019.12.27 |
| Hive Skewed (스큐) (0) | 2019.12.24 |
| Hive Partition 생성,수정,복구 (0) | 2019.12.21 |