Hive Map-Side-Join, Bucket-Map-Join, Sort-Merge-Join
Hive Map-Side-Join, Bucket-Map-Join, Sort-Merge-Join
· Version : Hive
Hive에서 조인 명령을 실행할때, 크기가 작은 테이블은 메모리에 캐시하고 크기가 큰 테이블은 맵퍼로 흘려 보낼 수 있다. 하이브는 메모리에 캐시한 작은 테이블로 부터 일치하는 모든 것을 찾아 낼 수 있기 때문에 맵에서 모든 조인을 할 수 있다. 이렇게 하면 일반 조인 시나리오에서 필요한 리듀스 단계를 제거할 수 있다.

데이터가 작을 수록 맵 사이드 조인은 일반 조인보다 효율이 좋다. 리듀스 단계를 제거할 뿐만 아니라 맵 단계 역시 줄어들기 때문이다.맵 사이드 조인을 활성화 하기 위해서는 hive.auto.convert.join 속성을 true로 설정해야한다. 기본값은 false 이다. 맵 사이드 조인을 사용하기 위한 테이블 크기 임계치는 hive.mapjoin.smalltable.filesize 속성값을 설정한다. 단위는 바이트 이다.
|
hive> set hive.auto.convert.join=true; hive> set hive.auto.convert.join.noconditionaltask=true; hive> set hive.auto.convert.join.noconditionaltask.size=20971520 hive> set hive.auto.convert.join.use.nonstaged=true; hive> set hive.mapjoin.smalltable.filesize = 30000000; |
맵 사이드 조인은 특정 조건에서는 큰 테이블에서도 사용할 수 있다. 이러한 조건은 ON 절에서 사용할 키에 대해서 버킷팅이 되어 있어야 하고, 한 테이블의 버킷 수가 다른 테이블 버킷 수의 배수이어야 한다. 이러한 조건이 충족되면 하이브는 다른 테이블의 각 버킷을 매칭하기 위해 모든 테이블의 내용을 가져올 필요 없이 테이블 간의 버킷에 대해 맵 사이드 조인을 할 수 있다. 이 옵션을 사용하기 위해서는 hive.optimize.bucketmapjoin 속성값을 ture로 설정해야 한다.
|
hive> set hive.optimize.bucketmapjoin=true; |
만약 버킷팅되어 있는 테이블이 같은 수의 버킷을 가지고 있고, 데이터는 조인/버킷 키로 정렬되어 있다면 하이브는 정렬-병합 조인(Sort Merge Join)을 수행하여 빠르게 조인할 수 있다.
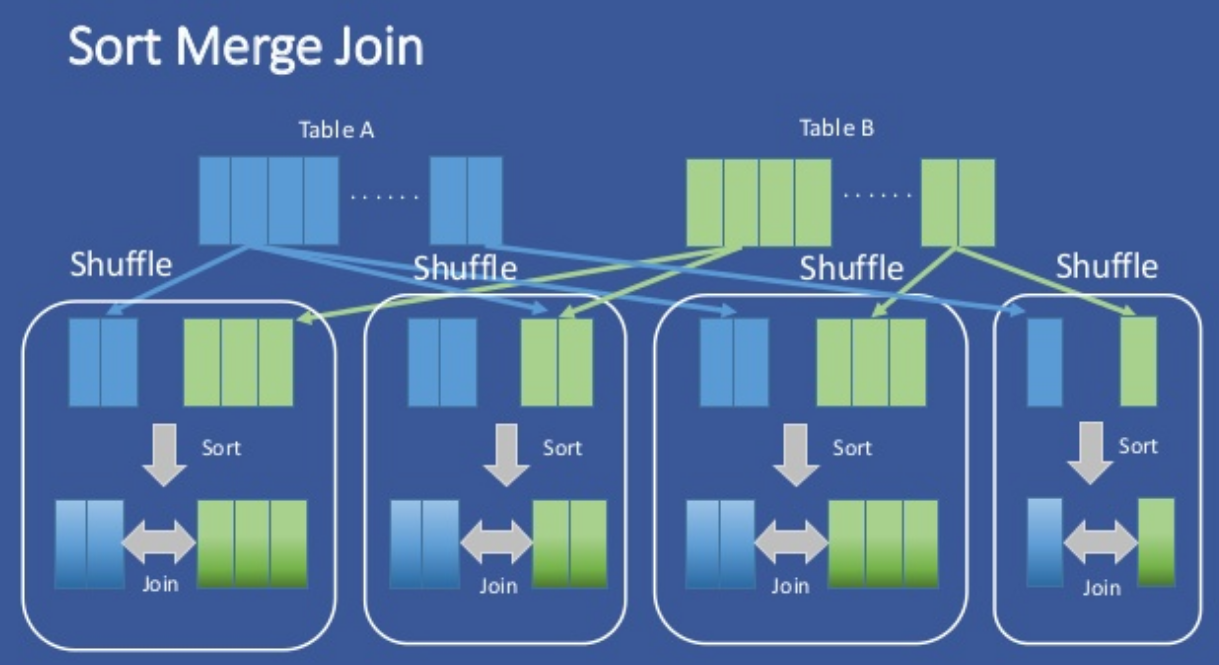
이 옵션을 사용하기 위해서는 아래 설정을 활성화 해야 한다.
|
hive> set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat; hive> set hive.optimize.bucketmapjoin=true; hive> set hive.optimize.bucketmapjoin.sortedmerge=true; |
참고자료
· Map Join in Hive | Map Side Join : https://data-flair.training/blogs/map-join-in-hive/
· Bucket Map Join in Hive – Tips & Working : https://data-flair.training/blogs/bucket-map-join/
· Sort Merge Bucket Join in Hive – SMB Join : https://data-flair.training/blogs/hive-sort-merge-bucket-join/
2020-07-28 / Sungwook Kang / http://sungwookkang.com
Hadoop, Big Data, 하둡, 빅데이터, 데이터분석, HDFS, 하둡 파일 시스템, Hive, 하이브, 하이브쿼리, HiveSQL, JOIN, Hive Map Join, Hive Bucket Join, Hive Sort Merge Join, 조인 최적화, 하이브 튜닝