Hive ORDER BY, SORT BY, DISTRIBUTE BY, CLUSTER BY
Hive ORDER BY, SORT BY, DISTRIBUTE BY, CLUSTER BY
· Version : Hive
하이브 또는 RDBMS에서 ORDER BY는 쿼리 결과 집합에 대해서 전체 정렬을 수행한다. 하이브에서 ORDER BY는 모든 데이터가 하나의 리듀서로 처리되기 때문에 데이터 셋이 클수록 시간이 오래 걸린다. ORDER BY에 오랜 시간을 수행될 수 있기 때문에 하이브는 hive.mapred.node가 strict로 설정되었을 경우 ORDER BY절에 대해서 LIMIT 를 요구한다. 기본값은 nonstrict 이다.
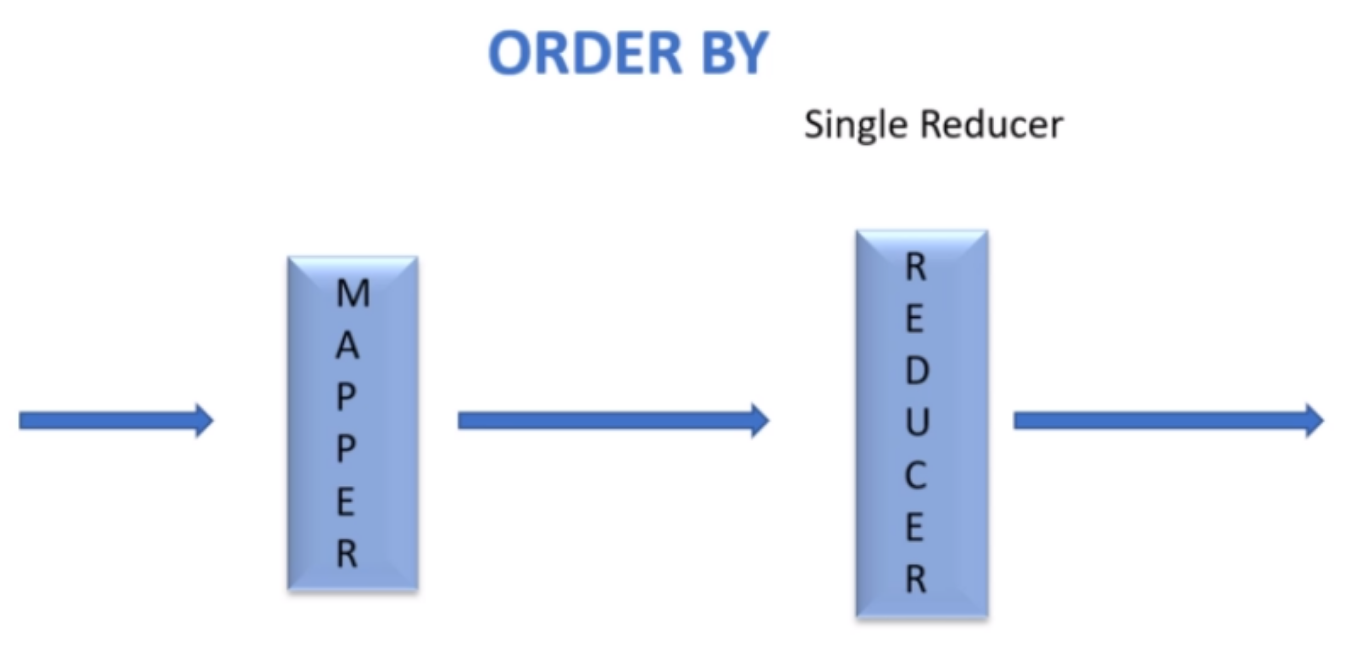
하이브에서 ORDER BY 대신 SORT BY를 사용하면 각 리듀서에서 지역 정렬하여 출력한다. ORDER와SORT를 사용할 경우 어떠한 컬럼이라도 지정할 수도 있고 ASC(기본값), DESC를 사용하여 정렬할 수도 있다. SORT BY를 사용하는 경우 하나 이상의 리듀서로 처리될 경우 각 리듀서의 파일이 정렬되어 있더라도 전체적으로는 다른 리듀서의 출력된 정렬 결과가 겹치기 때문에 전체 정렬순서는 보장되지 않는다.
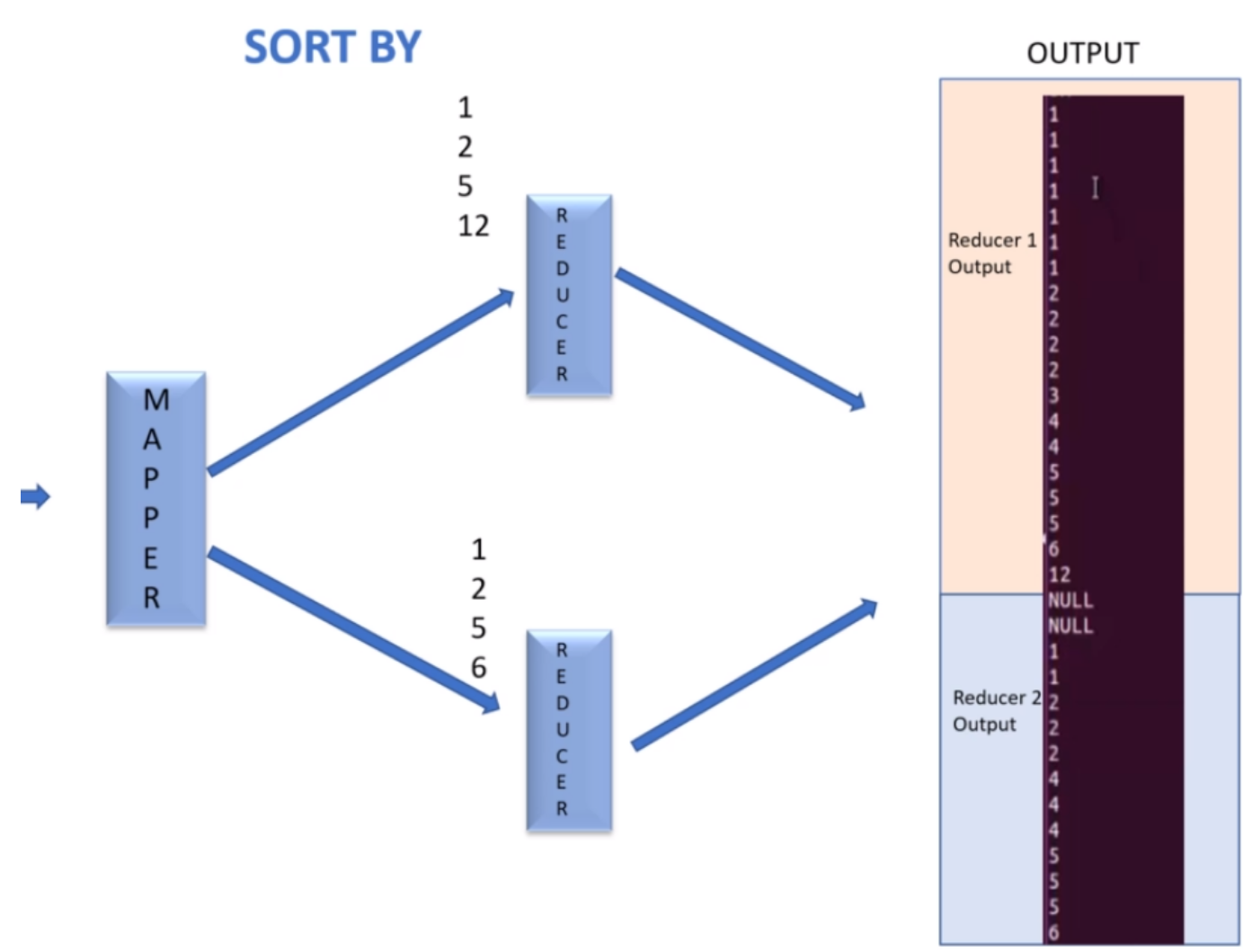
DISTRIBUTE BY는 맵의 출력을 리듀서로 어떻게 나누어 보내는지를 제어한다. 하이브는 쿼리를 맵리듀스 잡으로 변환할때 내부적으로 이 기능을 사용하기도 한다. 기본적으로 맵리듀스는 맵퍼가 출력하는 키에 대해서 해시값을 계산하고 해시값을 이용하여 카-값 쌍을 가용한 리듀서로 균등하게 분산하려고 노력한다. 이때 SORT BY를 사용할때 하나의 리듀서 출력이 다른 리듀서의 출력과 정렬 결과가 겹칠수 있다. 하지만 리듀서 출력 내에서는 정렬되어 있다. 하둡이 같은 데이터 레코드는 같은 리듀서로 보내는 것을 보장하기 위해서 DISTRIBUTE BY를 사용할 수 있다. 그리고 리듀서 별로 데이터를 정렬하기 위해 SORT BY를 사용한다.
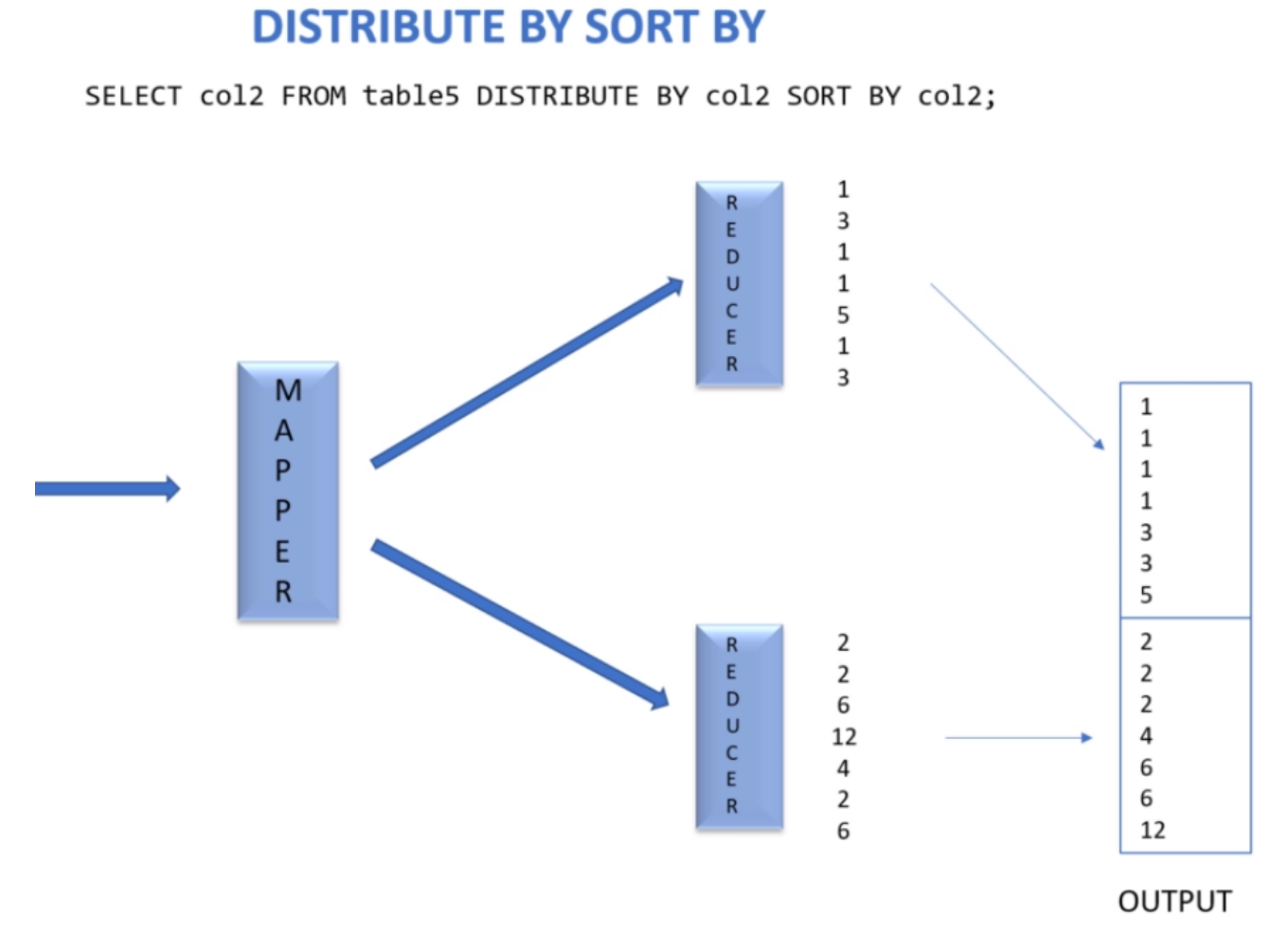
SORT BY는 리듀서 안에서 데이터 정렬을 제어하는 반면 DISTRIBUTE BY는 리듀서가 처리할 로우를 어떻게 받는지 제어한다는 점에서는 GROUP BY처럼 동작한다. 하이브는 SORT BY절 전에 DISTRIBUTE BY 절을 사용할 것을 요구하므로 주의해야한다.
CLUSTER BY는 같은 쿼리를 표현하는 간단한 방법이다.
2020-08-03 / Sungwook Kang / http://sungwookkang.com
Hadoop, Big Data, 하둡, 빅데이터, 데이터분석, HDFS, 하둡 파일 시스템, Hive, 하이브, 하이브쿼리, HiveSQL, 하이브 정렬, ORDER BY, SORT BY, DISTRIBUTE BY, CLUSTER BY