[Kafka] Kafka와 Debezium을 활용하여 SQL Server의 데이터를 실시간으로 PostgreSQL로 복제하기
[Kafka] Kafka와 Debezium을 활용하여 SQL Server의 데이터를 실시간으로 PostgreSQL로 복제하기
l Kafka 3.6.2, Debezium 2.5, SQL Server 2019, PostgreSQL 12
Kafka(이하 “카프카”)와 카프카 커넥터인 Debezium을 활용하여 SQL Server에서 발생하는 실시간 DML을 캡처하여 PostgreSQL로 데이터를 복제하는 방법에 대해서 알아본다. 이번 포스트에서는 실시간 데이터 복제를 위한 구성 정도로만 다루고, 각 단계에서의 상세한 기술 내용은 추후 다른 포스팅에서 다룰 예정이다.
[Architecture]
이번에 구축하려는 시스템의 아키텍처는 아래와 같다. 어플리케이션에서 MS SQL Server의 데이터를 변경하면 SQL Server의 CDC 기능을 사용하여 변경 사항을 캡처한다. Debezium은 변경 사항을 확인하여 Kafka로 데이터를 입력한다. 그리고 카프카에서 PostgreSQL로 실시간 데이터를 복제한다.

| 시스템 | 버전 |
| Kafka | 3.6.2 |
| Debezium | 2.5.1 |
| SQL Server | 2019 |
| PostgreSQL | 12 |
[카프카 설치]
카프카 설치는 아래 링크를 참고한다.
l [Kafka] Kafka 클러스터 4노드 구성 - Controller, Broker 혼합해서 구성하기 : https://sungwookkang.com/entry/Kafka-Kafka-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0-4%EB%85%B8%EB%93%9C-%EA%B5%AC%EC%84%B1-Controller-Broker-%ED%98%BC%ED%95%A9%ED%95%B4%EC%84%9C-%EA%B5%AC%EC%84%B1%ED%95%98%EA%B8%B0
[Debezium 커넥터 설치]
카프카에서 MS SQL Server과PostgreSQL에 연결하기 위한 Debezium 커넥터를 다운로드하여 설치한다.
l Debezium : https://debezium.io/releases/2.5/#installation

다운로드 후 압축을 해제한다. 필자의 경우 카프카 디렉터리에 plugins라는 디렉토리를 생성하여 파일을 위치하였다. 사용자에 따라 파일 위치를 다르게 가능하며, 이후 카프카 커넥터 설정에서 해당 위치의 경로를 지정하여 사용하기 때문에 경로가 달라도 상관없다.
| #SQL Server Connector tar xvf debezium-connector-sqlserver-2.5.0.Final-plugin.tar.gz -C /usr/local/kafka/plugins/ #PostgreSQL Connector tar -xvzf debezium-connector-jdbc-2.2.1.Final-plugin.tar.gz -C /usr/local/kafka/plugins/ |
[카프카에서 커넥터 설정 및 서비스 시작]
카프카에서 커넥터를 사용하기 위해 커넥터의 경로를 설정하고, 서비스를 시작한다. 카프카 디렉토리에서 connect-distributed.properties에서 아래 항목을 수정한다.
| cd /usr/local/kafka vi ./config/connect-distributed.properties |
| #Broker Node IP bootstrap.servers=XXX.XXXX.XXX.XXX:9092 #Debezium path plugin.path=/usr/local/kafka/plugins |
커넥터 서비스를 시작한다.
| cd /usr/local/kafka ./bin/connect-distributed.sh -daemon ./config/connect-distributed.properties |
커넥터가 정상적으로 실행되면 8083포트를 통해서 정보를 확인할 수 있다.
| curl localhost:8083/connector-plugins | jq |

[SQL Server CDC 활성화]
SQL Server에서 데이터의 변경을 실시간으로 캡처하기 위해서는 CDC 기능을 활성화한다. SQL Server CDC에 대한 자세한 내용은 아래 링크를 참고한다.
l Enable and disable change data capture : https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16
실습을 위한 데이터베이스 및 테이블을 생성한다. 테이블에는 반드시 Primary key 컬럼이 필요하다.
| CREATE DATABASE swkang_test GO USE swkang_test GO CREATE TABLE tbl_a( num int primary key, name nvarchar(50), reg_date datetime ) GO |
CDC 기능을 활성화한다.
| USE swkang_test GO -- CDC Enable Database EXEC sys.sp_cdc_enable_db GO /* EXEC sys.sp_cdc_disable_db GO */ -- CDC Enable Table EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'tbl_a', @role_name = '', @supports_net_changes = 1 GO /* EXEC sys.sp_cdc_disable_table @source_schema = N'dbo', @source_name = N'tbl_a', @capture_instance = N'dbo_tbl_a' */ |
데이터베이스가 CDC 활성화가 되었는지 확인하는 방법은 아래 스크립트를 사용한다.
| select name, is_cdc_enabled from sys.databases where is_cdc_enabled = 1 |

CDC 대상 테이블을 확인하는 방법은 아래 스크립트를 사용한다.
| Select name, is_tracked_by_cdc from sys.tables; |
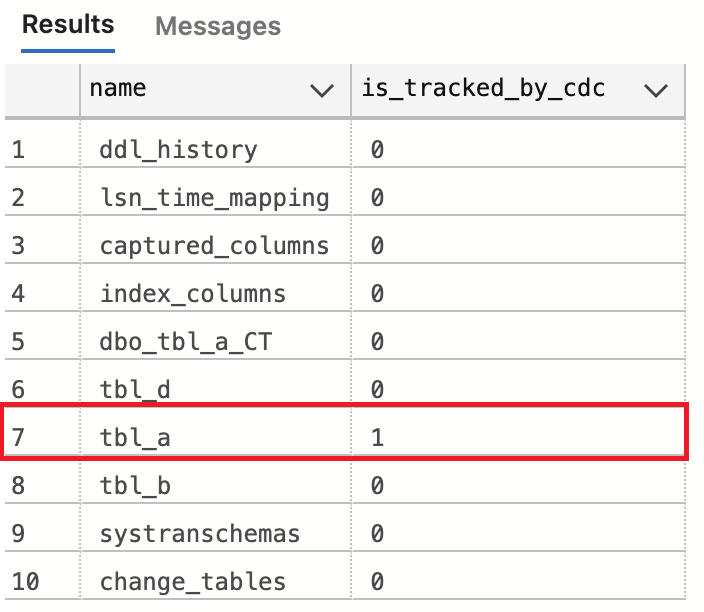
[Source Connector 정보 등록 (SQL Server)]
Debezium API를 사용하여, 소스 커넥터 정보를 입력한다. 필자는 postman 툴을 사용하여 API를 호출하였다. (각 속성에 대한 설명은 이번 포스트에서는 다루지 않는다.)
| http://kafka-ip:8083/connectors |
| { "name": "inventory-connector", "config": { "connector.class" : "io.debezium.connector.sqlserver.SqlServerConnector", "tasks.max": "1", "topic.prefix": "server1", "database.hostname" : "SQL Server IP", "database.server.name": "DB Name (Friendly name)", "database.port" : "1433", "database.user" : "swkang_cdc", "database.password" : "******", "database.names" : "swkang_test", "include.schema.changes": "true", "include.schema.comments" : "true", "tombstones.on.delete":"true", "schema.history.internal.kafka.bootstrap.servers" : "localhost:9092", "schema.history.internal.kafka.topic": "schema-changes.inventory1", "database.encrypt": "false" } } |
[Target Connector 정보 등록 (PostgreSQL)]
소스의 데이터를 타겟으로 복제하기 위해 타겟 데이터베이스인 PostgreSQL의 연결 정보를 등록한다. (각 속성에 대한 설명은 이번 포스트에서는 다루지 않는다.)
| { "name": "postgresql_target_sink", "config": { "connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector", "tasks.max": "1", "connection.url": "jdbc:postgresql://localhost/swkang_test", "connection.username": "cdc_user", "connection.password": "******", "insert.mode": "upsert", "delete.enabled": "true", "primary.key.mode": "record_key", "schema.evolution": "basic", "database.time_zone": "UTC", "topics": "server1.swkang_test.dbo.tbl_a" } } |
[실시간 데이터 복제 실습]
SQL Server에서 데이터를 입력한 다음 PostgreSQL에서 데이터를 확인한다. 이때 PostgreSQL에서는 테이블을 생성하지 않아도 SQL Server의 스키마 정보를 읽고 테이블을 자동으로 생성하고, 데이터를 복제한다.
SQL Server에서 아래 스크립트를 실행하여 데이터를 입력한다.
| insert into tbl_a values (1, 'a_skang1', 'skang1@nowcom.com') insert into tbl_a values (2, 'a_skang2', 'skang2@nowcom.com') insert into tbl_a values (3, 'a_skang3', 'skang2@nowcom.com') insert into tbl_a values (4, 'a_skang4', 'skang4@nowcom.com') insert into tbl_a values (5, 'a_skang5', 'skang5@nowcom.com') insert into tbl_a values (6, 'a_skang6', 'skang6@nowcom.com') insert into tbl_a values (7, 'a_skang6', 'skang6@nowcom.com') insert into tbl_a values (8, 'a_skang8', 'skang8@nowcom.com') |
PostgreSQL에서 데이터를 확인한다. 실시간으로 MS SQL Server의 데이터가 PostgreSQL로 복제된 것을 확인할 수 있다.

이번 포스트에서는 카프카의 Debezium을 활용하여 SQL Server에서 PostgreSQL로 복제를 진행하였다. Debezium 커넥터에서 제공하는 여러 커넥터를 활용하면 다양한 소스 데이터베이스에서 다양한 타겟 데이터베이스로 데이터를 실시간으로 복제할 수 있다.
[참고자료]
l Kafka Connect Elasticsearch Connector in Actio : https://www.confluent.io/blog/kafka-elasticsearch-connector-tutorial/
l How to Use Kafka Connect - Get Started : https://docs.confluent.io/platform/current/connect/userguide.html#connect-installing-plugins
l Debezium Release Series 2.5 : https://debezium.io/releases/2.5/
l Enable and disable change data capture : https://learn.microsoft.com/en-us/sql/relational-databases/track-changes/enable-and-disable-change-data-capture-sql-server?view=sql-server-ver16
2024-02-26 / Sungwook Kang / https://sungwookkang.com
KAFKA, 아파치 카프카, Apache Kafka, 데비지움, Debezium, 데이터복제, Kafka CDC, 카프카 스트림즈, 데이터 실시간 복제, 데이터 엔지니어