[Kafka] ksqlDB를 사용하여, SQL 구문으로 쉽고 빠르게 카프카 데이터 조회하기
[Kafka] ksqlDB를 사용하여, SQL 구문으로 쉽고 빠르게 카프카 데이터 조회하기
l Kafka 3.6.2, KsqlDB
Kafka(이하 “카프카”) 토픽에 저장되어 있는 데이터를 사용하기 위해서는 컨슈머라는 것이 필요하고, 컨슈머에는 각 비즈니스에 필요한 로직을 포함하여 원하는 데이터를 제공한다. 이렇게 시스템을 구성해 놓으면 빠르고 편리하게 메시징 처리를 할 수 있다. 그런데 실시간으로 카프카의 데이터를 조회(집계, 조인)하거나, 카프카 내부의 토픽 데이터를 조합해서 새로운 토픽 데이터 생성이 필요할 때가 있다. 이 경우 매번 컨슈머를 개발하거나 CLI를 통해 구축하는 것은 매우 번거롭고 익숙하지 않은 사용자에게는 어려운 작업일 수 있다. 이때 ksqlDB를 사용하면, 유사SQL문을 사용하여 데이터를 조회하거나, 스트림을 생성하거나, 실시간으로 다양한 작업을 할 수 있다.
이번 포스트에서는 ksqlDB가 무엇인지, 그리고 설치와 간단히 데이터를 조회하는 방법에 대해서 알아본다.
[ksqlDB 기능]
ksqlDB에서 제공하는 대표적인 기능은 다음과 같다.
l 저장된 데이터가 아닌 계속 움직이는 데이터를 처리하여 실시간 값 생성 : 비즈니스 전반에 걸쳐 생성된 데이터 스트림을 지속적으로 처리하여 데이터를 즉시 실행 가능하도록 한다.
l 스트림 처리 아키텍처 단순화 : ksqlDB는 데이터 스트림을 수집하고, 강화하며, 새롭게 파생된 스트림과 테이블에 대한 쿼리를 제공하기 위한 단일 솔루션을 제공한다.
l 간단한 SQL 구문으로 실시간 애플리케이션 구축 시작 : 친숙하고 가벼운 SQL 구문을 통해 관계형 데이터베이스에서 기존 애플리케이션을 구축하는 것과 마찬가지로 쉽고 친숙한 방식으로 실시간 애플리케이션을 구축할 수 있다.
ksqlDB에 대한 자세한 내용은 아래 링크를 참고한다.
l ksqlDB : https://ksqldb.io/
[ksqlDB 구성요소]

KsqlDB는 다음과 같은 요소로 구성되어 있다.
l ksqlDB 엔진: ksqlDB 엔진은 SQL 문과 쿼리를 실행한다. SQL 문을 작성하여 애플리케이션 논리를 정의하면 엔진이 사용 가능한 ksqlDB 서버에서 애플리케이션을 빌드하고 실행한다. 내부적으로 엔진은 SQL 문을 구문 분석하고 해당 Kafka Streams 토폴로지를 구축한다. ksqlDB 엔진은 KsqlEngine.java 클래스에서 구현된다.
l ksqlDB CLI: ksqlDB CLI는 ksqlDB 엔진용 명령줄 인터페이스가 포함된 콘솔을 제공한다. ksqlDB CLI를 사용하여 ksqlDB 서버 인스턴스와 상호 작용하고 스트리밍 애플리케이션을 개발한. ksqlDB CLI는 MySQL, Postgres 및 유사한 애플리케이션 사용자에게 친숙하도록 설계되었다. ksqlDB CLI는 io.confluent.ksql.cli 패키지에서 구현된다.
l REST 인터페이스: REST 서버 인터페이스를 사용하면 CLI, Confluent Control Center 또는 기타 REST 클라이언트에서 ksqlDB 엔진과 통신할 수 있다. ksqlDB REST 서버는 KsqlRestApplication.java 클래스에서 구현된다.
Ksql의 아키텍처 및 자세한 내용을 알고 싶다면 아래 링크를 참고한다.
l ksqlDB How it works : https://docs.ksqldb.io/en/latest/operate-and-deploy/how-it-works/
[ksqlDB 설치]
ksqlDB는 카프카에서 실행되므로 반드시 카프카가 실행되어 있어야 한다. 이번 포스트에서는 ksqlDB의 독립실행형 컨테이너로 설치한다.
도커 컴포즈 파일을 실행하여, 컨테이너를 실행한다.
docker-compose.yml
| version: '3.8' services: ksqldb-server: image: confluentinc/ksqldb-server hostname: ksqldb-server container_name: ksqldb-server ports: - "8088:8088" environment: KSQL_LISTENERS: http://0.0.0.0:8088 KSQL_BOOTSTRAP_SERVERS: 172.18.43.151:9092 KSQL_KSQL_LOGGING_PROCESSING_STREAM_AUTO_CREATE: "true" KSQL_KSQL_LOGGING_PROCESSING_TOPIC_AUTO_CREATE: "true" ksqldb-cli: image: confluentinc/ksqldb-cli container_name: ksqldb-cli entrypoint: /bin/sh tty: true |
[ksqlDB로 카프카 데이터 조회]
컨테이너가 정상적으로 실행되었으면, 아래 명령어로 ksqlDB에 접속한다. (이 포스트에서 실습 환경은 카프카와 ksqlDB가 같은 서버에서 운영중이다.)
| docker exec -it ksqldb-cli ksql http://ksqldb-server:8088 |

ksqlDB에서 사용할 수 있는 토픽 목록을 조회한다.
| show topics; |
토픽을 사용하여 카프카 스트림을 생성한다.
| create stream swkang ( payload STRUCT<before STRUCT<num int, name varchar, email varchar>, after STRUCT<num int, name varchar, email varchar>> ) WITH (kafka_topic = 'server1.swkang_test.dbo.tbl_a', value_format='json'); |
생성된 스트림 목록을 확인한다.
| show streams; |
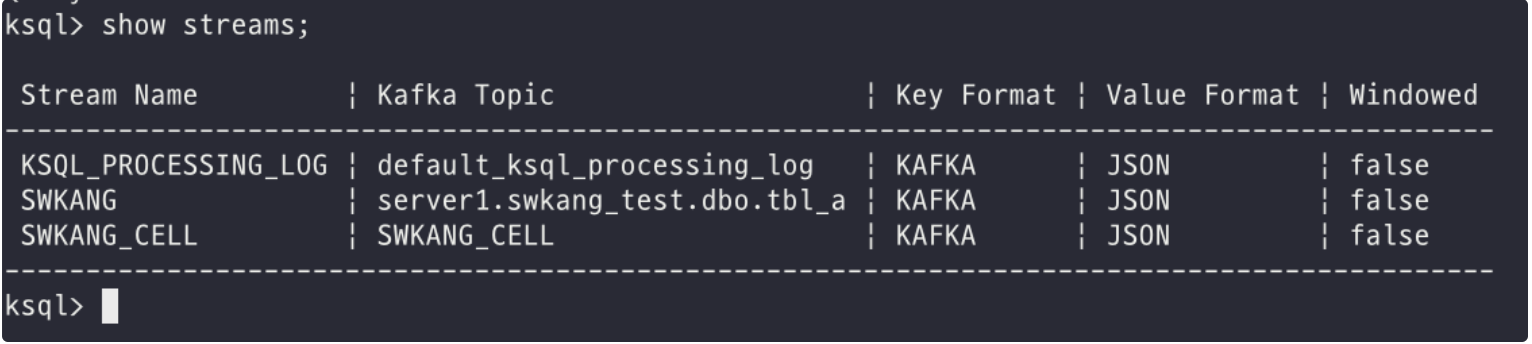
스트림의 데이터를 조회해 보자. 이때 조회 명령은 SQL문과 동일하다.
| select * from swkang; |

그런데 데이터를 살펴보니, 각 컬럼별로 나누어져 있지 않고, JSON 형태로 조회된 것을 볼 수 있다. 이러한 JSON 형태의 데이터를 각 컬럼 포맷으로 분리하기 위해서는 데이터 스트럭처를 제공해주어야 한다. 우선 데이터 스트럭처가 어떻게 되어 있는지 확인해 보자.
| describe swkang; |

이제 데이터를 조회할 때, 스트럭처 정보를 함께 제공하여 조회한다.
| SELECT PAYLOAD->"BEFORE"->"NUM" as before_num, PAYLOAD->"BEFORE"->"NAME" as before_name, PAYLOAD->"BEFORE"->"EMAIL" as before_email, PAYLOAD->"AFTER"->"NUM" as after_num, PAYLOAD->"AFTER"->"NAME" as after_name, PAYLOAD->"AFTER"->"EMAIL" as after_email FROM swkang; |

지금까지 ksqlDB 기능 및, 설치 방법과 카프카의 데이터를 조회하는 방법에 대해서 알아보았다. 이처럼 ksqlDB를 사용하면 편리하게 SQL문을 사용하여 데이터 조회 및 스트림 생성, 스트림 테이블 생성 등 다양한 작업들을 진행할 수 있다. ksqlDB에서 제공하는 쿼리문이 다양하므로, 공식 문서를 참고할 수 있도록 한다.
[참고자료]
l ksqlDB : https://ksqldb.io/
l ksqlDB How it works : https://docs.ksqldb.io/en/latest/operate-and-deploy/how-it-works/
2024-03-26 / Sungwook Kang / https://sungwookkang.com
KAFKA, 아파치 카프카, Apache Kafka, ksqlDB, 카프카 조회, 토픽 조회, 카프카 스트림즈, 데이터 실시간 조회, 데이터 엔지니어