[MySQL] MySQL(mariadb) Galera Cluster 장애 시나리오에 따른 다양한 복구 방법
[MySQL] MySQL(mariadb) Galera Cluster 장애 시나리오에 따른 다양한 복구 방법
l Version : MySQL(mariadb) Galera Cluster
Galera Cluster는 동기 복제를 사용하여 데이터를 복제하는 MySQL, MariaDB용 다중 마스터 클러스터이다. Galera Cluster를 사용하면 클러스터의 모든 노드가 마스터 역할을 하고 한 번에 모든 노드에 쓸 수 있다. Galera Cluster의 Active-Active 구성은 장애 조치가 없기 때문에 더 많은 로드 밸런싱과 내결함성을 제공한다.
l MySQL/MariaDB 환경에서 다중 마스터 복제를 지원하는 Galera Cluster 알아보기 : https://sungwookkang.com/entry/MySQLMariaDB-%ED%99%98%EA%B2%BD%EC%97%90%EC%84%9C-%EB%8B%A4%EC%A4%91-%EB%A7%88%EC%8A%A4%ED%84%B0-%EB%B3%B5%EC%A0%9C%EB%A5%BC-%EC%A7%80%EC%9B%90%ED%95%98%EB%8A%94-Galera-Cluster-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0
일단 구성되면 Galera Cluster는 큰 문제없이 작동할 수 있지만 여러 노드 오류로 인해 클러스터가 비정상적인 상황이 발생할 수 있다. 노드가 클러스터와의 통신이 되지 않으면 실패한 노드로 간주되는데, 하드웨어, 네트워크, 소프트웨어 오류 및 일반적인 사용자 실수로도 클러스터가 중단될 수 있다. 그래도 다행인 것은 하나라도 정상적인 노드가 있으면 클러스터 서비스의 연속성이 유지되어 데이터 손실이 발생하지 않는다. 이번 포스트에서는 Galera Cluster에서 장애가 발생하였을 때 클러스터를 복구하는 방법에 대해서 다뤄 본다.
클러스터 장애는 크게 세 가지 시나리오로 분류할 수 있다.
l 단일 노드 오류 (Single node failure)
l 다중 노드 오류 (Multi-node failure)
l 전체 클러스터 오류 (Full cluster failure)
이 중에 전체 클러스터 장애는 데이터베이스 연결이 완전히 끊어진 것으로 실제 장애 상황일수도 있으며, 일반 상황으로는 의도적으로 업데이트 및 정기 유지 관리로 인해 노드를 다시 시작하는 경우이다. 일반적인 상황에서는 노드가 정상적으로 재부팅 되면 클러스터에 다시 참여하고 클러스터의 나머지 부분과 동기화 된다. 노드가 재부팅 되는 동안 클러스터 상태에서 특정 노드가 누락되는 것은 정상적인 현상이고 이런 경우에는 클러스터 장애로 간주되지 않는다.
[정상 클러스터 확인]
장애가 발생했을 때 클러스터 상태를 신속하게 확인할 수 있도록 Galera Cluster가 정상인지 확인하는 방법을 아는 것이 중요하다. 아래 스크립트를 실행하면 현재 클러스터에 연결된 노드의 IP를 확인할 수 있다. 3개 노드로 구성된 정상 Galera Cluster는 데이터베이스 셸에서 다음과 같이 3개의 IP 목록이 표시된다.
| show status like 'wsrep_incoming_addresses'; |

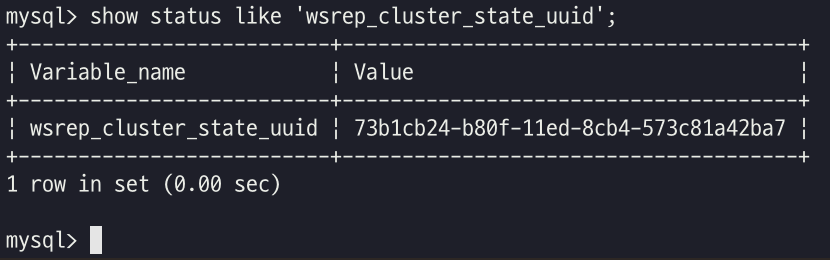
현재 클러스터 구성의 총 노드 수를 확인하려면 아래 스크립트를 실행한다. 전체 노드수와 현재 활성중인 노드수가 다르다면 일부 서버가 클러스터에서 제외된 상태로 확인이 필요하다.
| show status like 'wsrep_cluster_size'; |
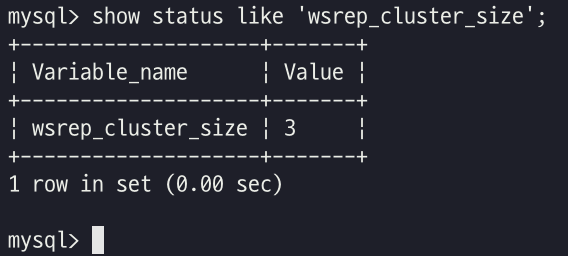
클러스터의 UUID를 검색하려면 아래 스크립트를 실행한다.
| show status like 'wsrep_cluster_state_uuid'; |
멤버 노드가 클러스터와 동기화되었는지 확인하려면 아래 스크립트를 실행한다. Synced 라고 표시되면 정상이다.
| show status like 'wsrep_local_state_comment'; |

[단일 노드 오류 복구]
이 시나리오에서는 클러스터의 노드 중 하나의 노드만 실패한 경우로, 데이터가 손실되거나 데이터베이스 연결이 중단되지는 않는다. 아래 스크립트를 실행하여 클러스터 정보를 조회하면 실패한 노드의 정보가 제외되고 활성중인 노드의 목록이 출력된다.
| show status like 'wsrep_incoming_addresses'; |
| mysql> show status like 'wsrep_incoming_addresses'; +--------------------------+-------------------------------+ | Variable_name | Value | +--------------------------+-------------------------------+ | wsrep_incoming_addresses | 10.0.0.51:3306,10.0.0.52:3306 | +--------------------------+-------------------------------+ |
클러스터에 참여한 노드 수에도 현재 장애가 발생한 노드 수를 제외하고 표시된다.
| show status like 'wsrep_cluster_size'; |
| mysql> show status like 'wsrep_cluster_size'; +--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 2 | +--------------------+-------+ |
실패한 노드를 복구하는 방법은 문제 해결 후 다시 클러스터에 조인하는 것이다. 간단한 문제의 경우 서비스 재시작으로 해결된다. MySQL 서비스를 시작하여 클러스터에 다시 조인되었는지 확인한다. 어떤 이유로든 다시 참여하지 못한 경우 MySQL(MariaDB)를 다시 시작한다.
| $ systemctl restart mysql |
[다중 노드 오류 복구]
이 시나리오에서는 하나를 제외한 모든 노드가 실패하여 쿼럼이 손실된 상태이다. 이 단계에서는 Galera Cluster가 더 이상 SQL 요청을 처리할 수 없다. 하지만 하나의 노드가 계속 실행 중이므로 데이터가 손실되지는 않는다. 그러나 실패한 노드가 다시 온라인 상태가 되면 클러스터가 존재하지 않기 때문에 클러스터에 다시 참여할 수 없다. 살아남은 노드에서 클러스터 크기 및 클러스터 상태 명령을 사용하여 이를 확인할 수 있다.
| show status like 'wsrep_cluster_size'; |
| +--------------------+-------+ | Variable_name | Value | +--------------------+-------+ | wsrep_cluster_size | 1 | +--------------------+-------+ |
| show status like 'wsrep_cluster_status'; |
| +----------------------+---------+ | Variable_name | Value | +----------------------+---------+ | wsrep_cluster_status | Primary | +----------------------+---------+ |
드문 경우지만 클러스터 상태 값이 non-Primary 로 표시될 수 있다. 이러한 오류는 쿼럼 손실뿐 아니라 네트워크 연결 손실일 수도 있다. 쿼럼 달성을 진행하기 전에 노드 클러스터 상태가 기본 값을 반환하는지 확인한다.
쿼럼 달성을 진행하기 전에 살아남은 노드에 실제로 최신 커밋이 있는지 확인해야 한다. 다른 노드가 클러스터에 다시 참여할 수 있도록 쿼럼을 재설정할 수 있는데, 자동과 수동으로 2가지 방법이 있다.
Automatic Bootstrap
쿼럼을 재설정하는 가장 간단한 방법은 자동 부트스트랩을 사용하는 것이다. 데이터베이스 셸에서 다음 명령을 실행하여 노드를 자동 부트스트랩 할 수 있다. 그러면 살아남은 노드가 기본 시작 노드가 되도록 부트스트랩 되므로 실패한 다른 노드가 클러스터에 다시 참여할 수 있다.
| set global wsrep_provider_options='pc.bootstrap=YES'; |
Manual Bootstrap
다음 명령을 실행하여 노드를 수동으로 부트스트랩 한다. 기본 노드가 실행되면 나머지 모든 노드에서 한 번에 하나씩MySQL(mariadb) 서비스를 다시 시작한다.
| $ systemctl stop mysql $ galera_new_cluster $ systemctl restart mysql |
[전체 클러스터 장애 복구]
이 시나리오에서는 모든 노드가 실패했거나 정상적으로 종료되지 않은 경우이다. 전체 쿼럼 손실이 발생했으며 클러스터가 SQL 요청을 수락하지 않는다. 이와 같은 심각한 장애가 발생한 후 모든 노드가 다시 온라인 상태가 되더라도 MySQL(mariadb) 서비스를 시작할 수 없다. 이는 비정상적으로 종료되어 어떤 노드도 마지막 커밋을 수행할 수 없었기 때문이다. Galera Cluster는 다양한 방식으로 장애가 발생될 수 있으며 이로 인해 전체 장애를 복구하는 방법도 다양하다.
가장 높은 seqno 값을 기반으로 한 복구
이 방법은 클러스터 중에 하나 이상의 노드가 정상적으로 종료될 가능성이 약간이라도 있는 경우 사용할 수 있다. 최신 데이터를 가진 노드는 장애가 발생한 클러스터의 모든 노드 중에서 가장 높은 seqno 값을 갖게 된다. /var/lib/mysql/grastate.datseqno의 내용을 확인해보면 seqno 값을 보여주는 내용에서 단서를 찾을 수 있다. 장애 성격에 따라 모든 노드가 동일한 음수의 seqno 값을 갖거나 노드 중 하나가 가장 높은 양수의 seqno 값을 갖게 된다.
다음은 노드3의 grastate.dat 내용이다. 이 노드에는 음수의 seqno가 있고 그룹 ID(uuid)정보가가 없다. DDL(데이터 정의 언어) 처리 중에 노드 장애가 발생한 경우이다.
| $ cat /var/lib/mysql/grastate.dat # GALERA saved state version: 2.1 uuid: 00000000-0000-0000-0000-000000000000 seqno: -1 safe_to_bootstrap: 0 |
다음은 노드2의 grastate.dat 내용이다. 이 노드는 트랜잭션 처리 중에 장애가 발생하여 seqno가 음수이지만 그룹 ID(uud) 정보를 가지고 있다.
| $ cat /var/lib/mysql/grastate.dat # GALERA saved state version: 2.1 uuid: 886dd8da-3d07-11e8-a109-8a3c80cebab4 seqno: -1 safe_to_bootstrap: 0 |
다음은 노드1의 grastate.dat 내용이다. seqno 값이 가장 높은 것을 확인할 수 있다. (물론 사용자 노드마다 가장 높은 seqno의 노드는 다를 것이다.) 노드가 정상적으로 종료될 수 있을 때 노드는 양수로 가장 높은 seqno 값을 갖게 된다. 이 경우 먼저 복구해야 할 노드이다.
| $ cat /var/lib/mysql/grastate.dat # GALERA saved state version: 2.1 uuid: 886dd8da-3d07-11e8-a109-8a3c80cebab4 seqno: 31929 safe_to_bootstrap: 1 |
모든 노드의 seqno 값이 -1, safe_to_bootstrap 값이 0으로 되어 있는 경우전체 클러스터 장애가 발생했음을 나타낸다. 이 시점에서 galera_new_cluster 명령을 사용하여 클러스터를 새로 생성하여 시작할 수 있다. 그러나 각 노드가 동일한 데이터베이스 데이터 복사본을 가지고 있는지 알 수 있는 방법이 없으므로 권장하지 않는다.
노드 1을 다시 시작하기 전에 클러스터 구성 파일 (/etc/my.cnf.d/server.cnf)를 변경하여 클러스터 노드의 IP에 대한 정보를 제거해야 한다. 다음은 변경 전 구성의 [galera] 섹션 내용이다.
| [galera] # Mandatory settings wsrep_on=ON wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_address="gcomm://10.0.0.51,10.0.0.52,10.0.0.53" wsrep_cluster_name='galeraCluster01' wsrep_node_address='10.0.0.51' wsrep_node_name='galera-01' wsrep_sst_method=rsync binlog_format=row default_storage_engine=InnoDB innodb_autoinc_lock_mode=2 |
wsrep_cluster_address모든 구성원 노드의 IP가 표시된다. 다음과 같이 주소를 제거해야 한다.
| wsrep_cluster_address="gcomm://" |
이제 이 노드에서 MySQL(mariadb) 서비스를 다시 시작할 수 있다.
| $ systemctl restart mysql |
서비스가 성공적으로 시작되었는지 확인되었으면, 다른 노드에서 한 번에 하나씩 서비스를 다시 시작할 수 있도록 한다. 모든 노드가 성공적으로 실행되었으면 노드1의 클러스터 구성을 편집하여 모든 구성원 노드의 IP 주소를 추가하고 서비스를 다시 시작한다.
| wsrep_cluster_address="gcomm://10.8.8.53,10.8.8.54,10.8.8.55" |
이 시점에서는 Galera Cluster가 실행 중이어야 하며 모든 노드는 활성중인 노드와 동기화 되어야 한다.
마지막 커밋을 기준으로 복구
이는 모든 노드가 완전히 중단되어 seqno 값이 -1이 되는 Galera Cluster 장애의 최악의 시나리오이다. 이 경우에는 앞서 언급한 것처럼 노드에서 galera_new_cluster 명령을 실행한 다음 나머지 노드를 클러스터에 다시 연결하는 방식을 실행할 경우, 새로운 ID 세트로 새 클러스터가 생성되고 다른 모든 노드가 여기에 합류하여 완전한 동기화를 시작하기 때문에 데이터가 손실될 수 있다.
마지막 커밋이 있는 노드를 확인하려면 각 노드에서 wsrep_last_commit 값을 개별적으로 확인할 수 있다. 가장 높은 값을 가진 노드는 가장 최근에 커밋된 노드이다. 가장 높은 커밋 값을 가진 노드를 부트스트랩하여 클러스터를 시작한 다음 다른 구성원들은 클러스터 노드에 합류할 수 있다. 이 프로세스는 이전 섹션에서 본 것처럼 가장 높은 seqno를 가진 노드를 부트스트래핑하는 것과 유사하다.
모든 노드의 MySQL(mariadb) 서비스를 중지한다.
| $ systemctl stop mariadb |
/etc/my.cnf.d/server.cnf의 [galera] 섹션에서 wsrep_cluster_address를 편집하여 멤버 노드에 대한 정보를 제거한다.
| wsrep_cluster_address="gcomm://" |
MySQL(mariadb) 서비스를 시작한다.
| $ systemctl start mariadb |
데이터베이스 셸에서 마지막으로 커밋된 값을 확인한다.
| mysql> show status like 'wsrep_last_committed'; +----------------------+---------+ | Variable_name | Value | +----------------------+---------+ | wsrep_last_committed | 319589 | +----------------------+---------+ |
모든 노드에서 마지막으로 커밋된 값을 확인한다. 최신 데이터를 가진 노드가 가장 높은 값을 갖게 된다. 커밋된 값이 가장 높은 노드에서 새 클러스터를 만든다.
| $ galera_new_cluster |
wsrep_cluster_address 나머지 노드의 값을 변경하여 IP 주소를 추가한 다음 한 번에 한 노드씩 MySQL(mariadb) 서비스를 다시 시작한다. 클러스터가 실행 중이어야 하며 데이터 동기화가 모든 변경 사항을 커밋해야 한다. 잠시 후 모든 노드에서 마지막으로 커밋된 값을 확인하여 노드가 현재 동기화되어 있는지 확인한다.
[참고자료]
l How To Recover MariaDB Galera Cluster After Partial or Full Crash : https://www.symmcom.com/docs/how-tos/databases/how-to-recover-mariadb-galera-cluster-after-partial-or-full-crash
2023-10-17 / Sungwook Kang / http://sungwookkang.com
MySQL Galera Cluster, 갈레라 클러스터, MySQL PXC, 클러스터 장애 복구, 갈레라 클러스터 복구, Recovery Galera Cluster