Python에서 Tesseract 사용하기
Python에서 Tesseract 사용하기
· Version : MAC OS, Python 3.X, PIP3
이전 포스트에서 Tesseract 오픈소스 소프트웨어를 사용하여 이미지에 포함된 문자열을 추출하는 방법에 대해서 알아 보았다.
· Tesseract를 활용한 이미지 속 문자인식 : https://sungwookkang.com/1475
다른 포스트에도 언급한바 있지만, 이미지의 경우 배경 색상이나, 글꼴, 언어 타입에 따라 인식률에 차이가 크므로, 전처리 과정이 수반되어야 어느정도 정확도를 높일 수 있다. OpenCV등 오픈소스로 공개된 다양한 이미지 처리 모듈을 사용하기 위해서는 파이썬을 활용할 수 있는데, 그 시작으로 파이썬에서 Tesseract를 임포트하여 사용하는 방법을 설명한다. 이번 포스트의 내용을 따라하기 전에, Tesseract 프로그램이 설치되어 있어야 한다.
Python3.X 와 PIP3를 설치 한다. 그리고 아래 명령을 사용하여 Tesseract패키지를 설치 한다. 설치과정에서 Permission 문제가 발생하면 –user 명령을 함께 사용한다.
|
pip3 install pytesseract --user pip3 install opencv-python --user |
Python3를 실행하여 아래 코드를 작성한다.
|
from PIL import Image from pytesseract import * import re import cv2
img = Image.open('이미지파일명')
text = pytesseract.image_to_string(img,lang='euc') #한글은 'kor' #간혹 lang로 오류가 발생할경우, lang 파라메터 제거 #text = pytesseract.image_to_string(img)
print(text) |
아래 결과는 인터넷에서 어느 식당에서 메뉴 사진을 찍은 이미지에서 메뉴와 가격을 추출한것이다. 아직 데이터가 정제되지 않은 상태이며 한글과 영어가 섞여 있는데, 한글은 판독하지 못한것을 확인할 수 있다.
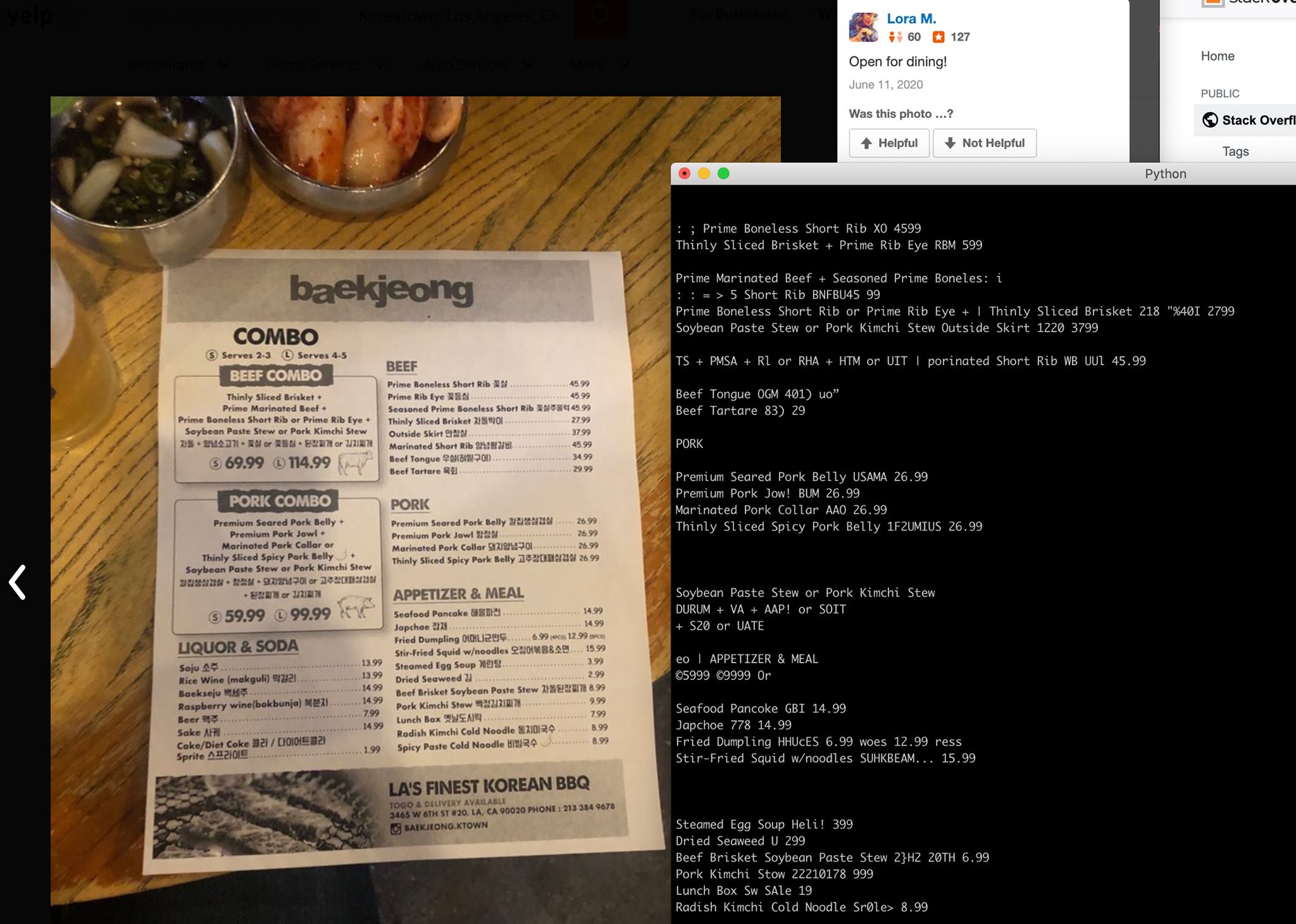
실제 추출된 문자열에서 데이터로 활용하려면, 이미지 인식 개선, 다양한 문자열 인식, 데이터 가공을 통한 유요한 데이터 추출 등의 작업이 추가되어야 한다. 이러한 작업을 하나의 프로그램으로 만들기 위해서 오늘 실습한 코드에서 점진적으로 코드가 추가될 예정이다.
2020-12-18/ Sungwook Kang / http://sungwookkang.com
이미지 인식, OCR, Tesseract, 문자열 인식, OpenCV, 딥러닝, 머신러닝, 글자 인식, 이미지 분석, 파이선, 파이썬, python