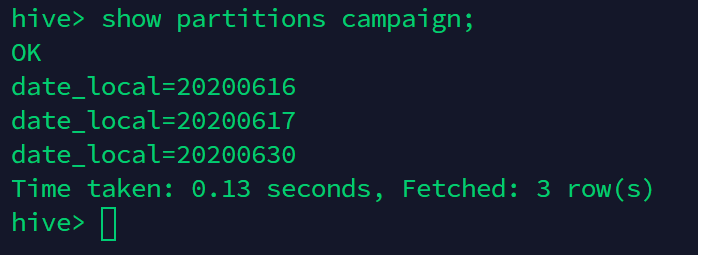
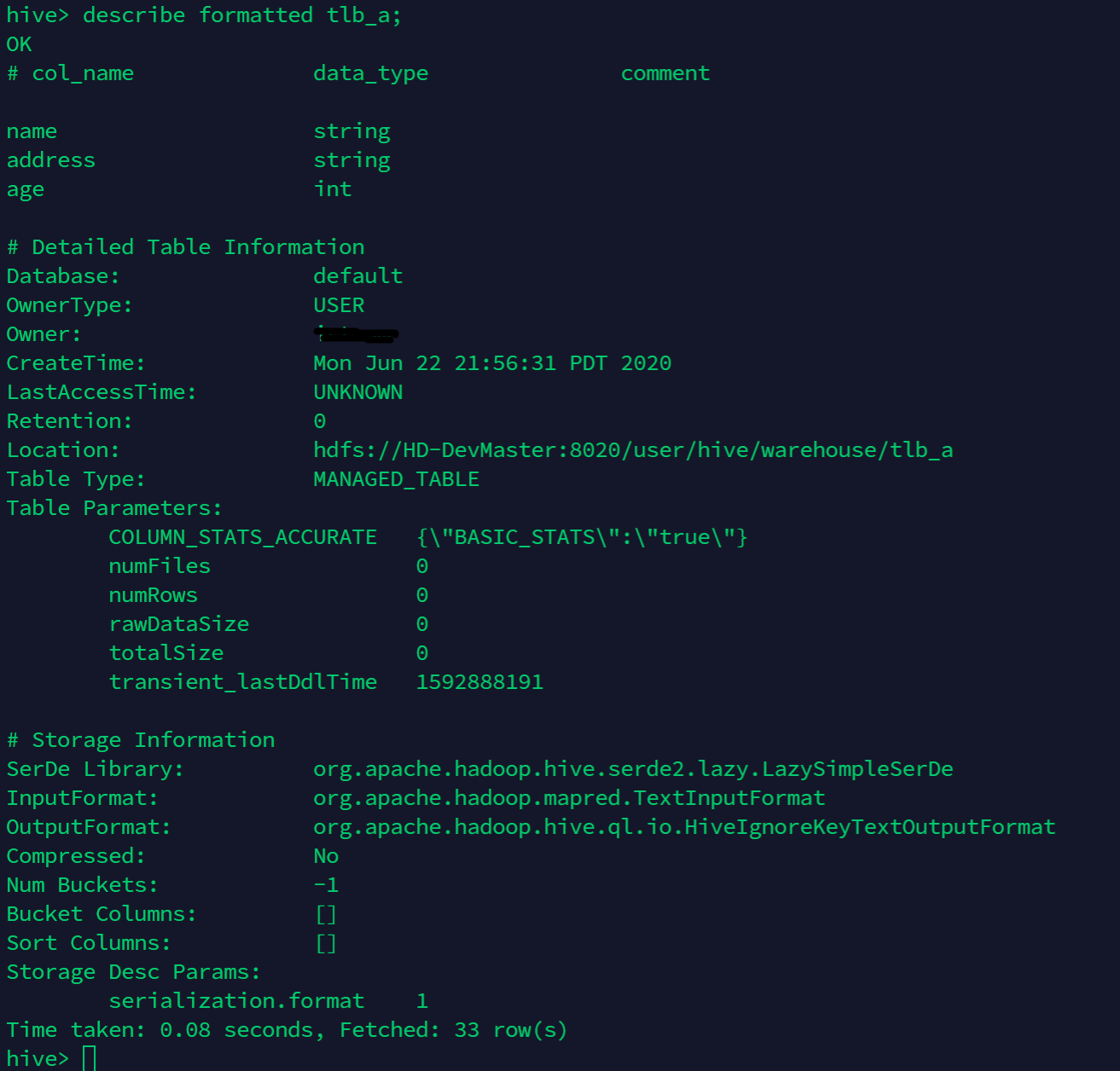
Hive 테이블 삭제, 수정 · Version : Hive 하이브에서 테이블을 삭제하는 명령은 DROP TABLE 명령어를 사용한다. DROP TABLE IF EXISTS table_name; 테이블을 삭제할때, 하둡의 휴지통기능이 활성화되어 있으면 데이터는 분산 파일 시스템의 .Trash 디렉터리로 이동된다. 휴지통 기능에 설정된 시간이후 데이터가 완전히 삭제 된다. 휴지통 기능이 비활성화 되어 있는 경우 즉시 삭제된다. 또한 삭제하려는 테이블이 외부 테이블인경우, 테이블의 메타데이터만 삭제되며 데이터는 그대로 남아있다. 테이블 수정은 ALTER TABLE 명령을 사용하여 변경한다. 테이블 수정은 메타데이터만 변경할 뿐 데이터 자체는 변경시키지 않는다. [테이블명 변경] Table_name 테이블명을 ..