ZooKeeper 클라이언트 요청 처리
· Version : Zookeeper
주키퍼의 모든 서버는 클라이언트로 부터 읽기, 쓰기 요청을 받을 수 있다. 읽기 요청은 클라이언트가 접속한 서버의 로컬 데이터를 이용한다. 쓰기 요청을 받은 서버는 리더 서버로 리다이렉트 한다.

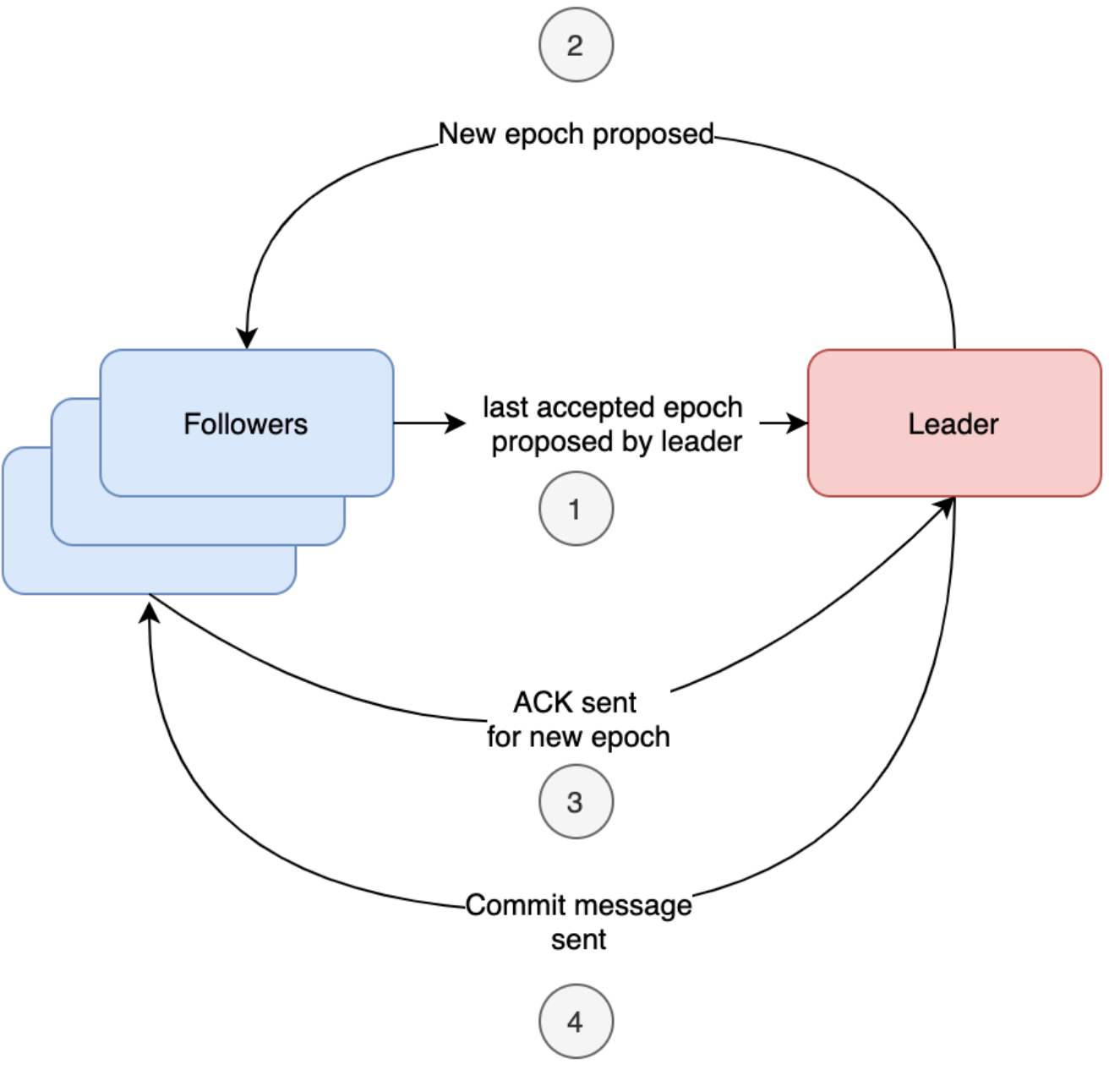
리더는 새로운 트랜잭션아디이(zxid)를 생성한 후 모든 팔로워에게 쓰기 요청을 보낸다. 쓰기 요청을 받은 서버는 자기의 로컬 트랜잭션 로그 파일에 처리 내역을 저장하지만 실제 메모리에는 반영하지 않고, 리더로 ACK 신호를 보낸다. 리더는 과반수 이상의 팔로워로부터 ACK 신호를 받으면 메모리에 반영하라고 하는 커밋 신호를 보낸다. 커밋 신호를 받은 팔로워는 자신의 메모리에 쓰기 요청된 정보를 반영한다. 팔로워 중 클라이언트로 부터 요청을 받은 서버는 클라이언트로 처리 결과를 보낸다. 아래 그림에서 순서를 쉽게 확인할 수 있다.
주피커는 이벤추얼한 정합성을 가지고 있는데, 동일 데이터에 대해 쓰기나 읽기가 서로 다른 클라이언트에서 서로 다른 주키퍼 서버에 접속하면 읽기 연산을 수행하는 클라이언트에는 반영되기 전의 데이터가 읽혀질 가능성이 크다. 그래서 강한 정합성을 필요로 하는 애플리케이션이나 기능에서는 sync() 메소드를 이용하여 해결할 수 있다. Sync() 메소드는 파라미터로 전달된 패스에 대해 모든 주키퍼 서버가 처리 중인 쓰기 연산을 로컬 메모리에 모두 반영하는것을 보장하는 메소드다.
주키퍼 서버에 장애가 발생하면 클라이언트 측에서는 Disconnected 이벤트가 발생하고, 클라이언트 라이브러리에서는 자동으로 다른 서버로 접속을 시도한다. 주키퍼 클라이언트는 자신이 실행한 최종 트랜잭션 아이디(zxid)를 메모리에서 관리한다. 주키퍼 서버는 자신의 트랜잭션아이디보다 큰 값을 가지고 있는 클라이언트의 접속 요청은 거절한다.
2020-05-17 / Sungwook Kang / http://sungwookkang.com
Hadoop, Big Data, 하둡, 빅데이터, 데이터분석, 주키퍼, Zookeeper, 분산 코디네이션
'SW Engineering > Hadoop' 카테고리의 다른 글
| ZooKeeper 옵저버와 CLI (0) | 2020.05.19 |
|---|---|
| Hive에서 쉘 명령 실행 (0) | 2020.05.18 |
| ZooKeeper 멀티 서버 구성 (0) | 2020.05.17 |
| ZooKeeper 리더선출과 데이터 ACID 정책 (0) | 2020.05.14 |
| Zookeeper 세션(Session) (0) | 2020.05.13 |