[AWS Aurora] Aurora Storage Engine
l Version : Aurora
Amazon Aurora 스토리지 엔진은 한 지역의 여러 AWS 가용 영역(AZ)에 걸쳐 있는 분산 SAN 이다. AZ는 물리적 데이터센터로 구성된 논리적 데이터센터 이다. 각 AZ는 해당 지역의 다른 AZ와 빠른 통신을 허용하는 짧은 지연 시간 링크를 제외하고 다른 AZ와 격리되어 있다. Amazon Aurora의 중심에 있는 분산형 저지연 스토리지 엔진은 AZ에 의존한다.
Amazon Aurora는 현재 보호 그룹이라고 하는 10GB의 논리 블록에 스토리지 볼륨을 구축한다. 각 보호 그룹의 데이터는 6개의 스토리지 노드에 복제된다. 그런 다음 이러한 스토리지 노드는 Amazon Aurora 클러스터가 있는 리전의 3개 AZ에 할당된다.
클러스터가 생성될 때에는 매우 적은 양의 스토리지를 사용한다. 데이터 볼륨이 증가하고 현재 할당된 스토리지를 초과하면 Aurora는 수요를 충족하도록 볼륨을 원활하게 확장하고 필요에 따라 새 보호 그룹을 추가한다. Amazon Aurora는 현재 64TB에 도달할 때까지 이러한 방식으로 계속 확장된다.

Amazon Aurora에서 데이터를 쓰기가 발생하면 6개의 스토리지 노드에 병렬로 전송된다. 이러한 스토리지 노드는 3개의 가용 영역에 분산되어 있어 내구성과 가용성이 크게 향상된다. 각 스토리지 노드에서는 레코드는 먼저 메모리 내 대기열에 들어간다. 이 대기열의 로그 레코드는 중복 제거된다. 예를 들어, 마스터 노드가 스토리지 노드에 성공적으로 쓰기 작업을 했으나 마스터와 스토리지 노드 간의 연결이 끊긴 경우 마스터 노드는 로그 기록을 재전송하지만 중복된 로그 기록은 폐기한다. 유지해야하는 기록은 핫 로그의 디스크에 저장된다.

레코드가 지속되면 로그 레코드는 업데이트 대기열이라는 메모리 내 구조에 기록된다. 업데이트 대기열에서 로그 레코드는 먼저 병합된 다음 데이터 페이지를 만드는데 사용된다. 하나 이상의 LSN(Log Sequence Number)이 누락된 것으로 확인되면 스토리지 노드는 프로토콜을 사용하여 볼륨의 다른 노드에서 누락된 LSN을 검색한다. 데이터페이지가 업데이트되면 로그 레코드가 백업되고 가비지 수집용으로 표시된다. 그런 다음 페이지는 Amazon S3에 비동기식으로 백업 된다. 쓰기가 핫 로그에 기록되어 지속 가능하게 되면 스토리지 노드는 데이터 수신을 확인한다. 6개의 스토리지 노드 중 4개 이상이 수신을 확인하면 쓰기가 성공한 것으로 간주되고 클라이언트 애플리케이션에게 성공을 반환한다.

Amazon Aurora가 다른 엔진보다 훨씬 빠르게 쓸 수 있는 이유 중 하나는 로그 레코드를 스토리지 노드에만 보내고 이러한 쓰기가 병렬로 수행되기 때문이다 실제로 Amazon Aurora는 데이터가 6개의 다른 노드에 기록되고 있음에도 불구하고 평균적으로 MySQL과 비교하여 유사한 워크로드에 대해 약 1/8 IOPS가 필요한다. 이 프로세스의 모든 단계는 비동기 방식이다. 쓰기는 그룹 커밋을 사용하여 병렬로 수행되어 대기 시간을 줄이고 처리량을 향상 시킨다. 쓰기 지연 시간이 짧고 I/O 풋프린트가 감소한 Aurora는 쓰기 집약적인 애플리케이션에 이상적이다.
아래 다이어그램은 3개의 AZ에 저장된 데이터를 보여준다 복제된 데이터는 99.999999999%의 내구성을 제공하도록 설계된 S3에 지속적으로 백업 된다.

이 설계를 통해 Amazon Aurora는 클라이언트 애플리케이션에 대한 가용성 영향 없이 전체 AZ 또는 2개의 스토리지 노드 손실을 견딜 수 있다.
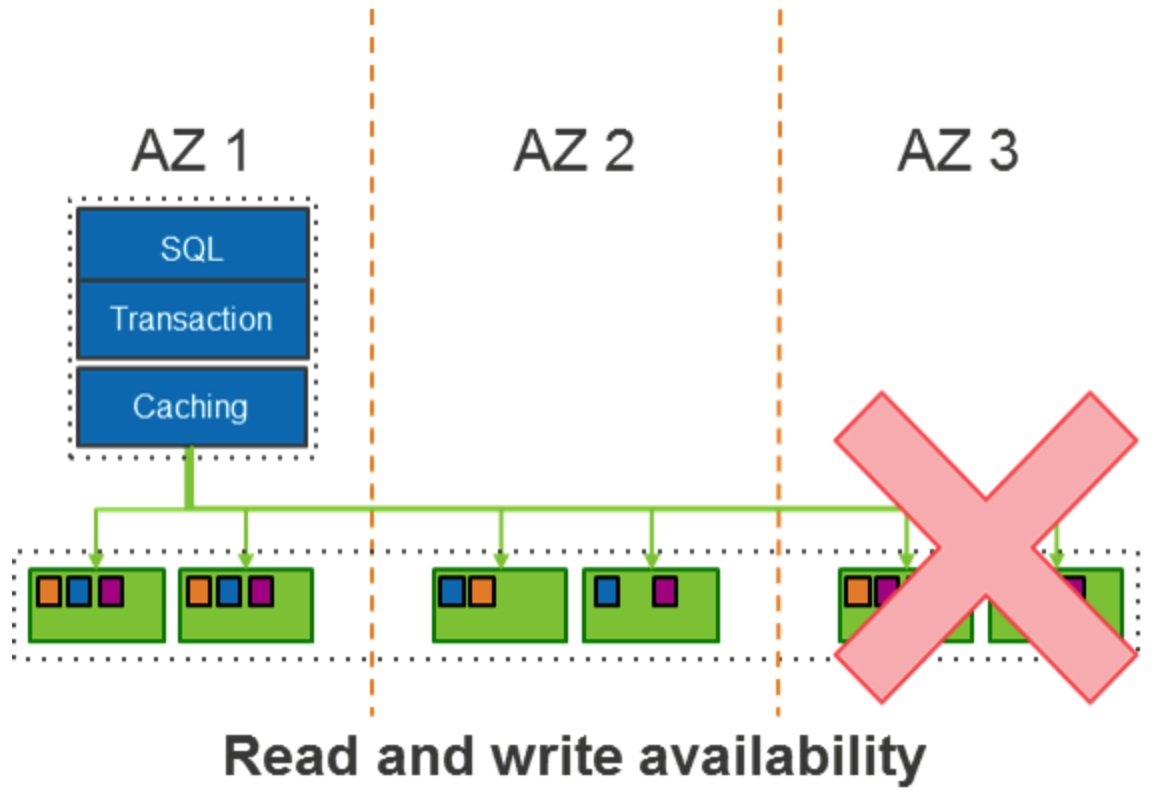
복구 중에 Aurora는 데이터 손실 없이 보호 그룹에 있는 AZ와 또 다른 스토리지 노드의 손실을 유지하도록 설계 되었다. 이는 보호 그룹에 있는 4개의 스토리지 노드에 지속된 경우에만 Aurora에서 쓰기가 지속되기 때문이다. 쓰기를 수신한 3개의 스토리지 노드가 다운 되더라도 Aurora는 여전히 4번째 스토리지 노드에서 쓰기를 복구 할 수 있다. 복구 중 읽기 쿼럼을 달성하기 위해 Aurora는 3개의 스토리지 노드가 동일한 LSN을 따라 잡는지 확인한다. 그러나 쓰기를 위해서 볼륨을 열기 위해 Aurora는 향후 쓰기를 위한 쓰기 쿼럼을 달성할 있도록 4개의 스토리지 노드가 복구될 때까지 기다려야 한다.

읽기의 경우 Aurora는 읽기를 수행할 갖아 가까운 스토리지 노드를 찾으려고 한다. 각 읽기 요청은 타임스탬프, 즉 LSN과 연결된다. 스토리지 노드는 LSN에 도달한 경우 (해당 LSN까지의 모든 업데이트를 수신한 경우) 읽기를 수행할 수 있다. 하나이상의 스토리지 노드가 다운되거나 다른 스토리지 노드와 통신할 수 없는 경우 해당 노드는 가십 프로토콜을 사용하여 온라인 상태가 될 때 자신을 재동기화 한다. 스토리지 노드가 손실되고 그 자리를 대신할 새 노드가 자동으로 생성되는 경우에도 가십 프로토콜을 통해 동기화 된다.
Amazon Aurora를 사용하면 컴퓨팅과 스토리지가 분리된다. 이를 통해 Aurora 복제본은 복제본 자체의 데이터를 유지하지 않고도 스토리지 계층에 대한 컴퓨팅 인터페이스 역할을 할 수 있다. 이렇게 하면 데이터를 동기화할 필요 없이 인스턴스가 온라인 상태가 되는 즉시 Aurora 복제본이 트래픽 제공을 시작할 수 있다. 마찬가지로 Aurora 복제본의 손실은 기본 데이터에 영향을 미치지 않는다 Aurora 복제본이 마스터 노드가 되면 데이터 손실이 없다. 최대 15개의 Aurora 복제본을 지원하고 로드 밸런싱하기 때문에 Aurora는 고가용성, 읽기 집약적 워크로드에 적합하다.
Aurora는 성능에 영향없이 특정 시점에 대한 클러스터의 데이터 스냅샷을 생성할 수 있다. 또한 백업에서 복원할 때 10GB보호 그룹은 병렬로 복원한다. 또한 보호 그룹이 복원된 후 에는 로그를 다시 적용할 필요가 없다. 즉, 보호 그룹이 복원되는 즉시 Amazon Aurora가 최고 성능으로 작동할 수 있다.
Aurora는 AES-256 암호화를 사용하여 모든 저장 데이터를 암호화 할 수 있다. 사용자는 AWS Key Management Service (AWS KMS)를 사용하여 키를 관리 할 수도 있다. 또한 TLS 연결을 통해 전송 중인 데이터를 보호할 수 있다.
[참고자료]
l https://aws.amazon.com/ko/blogs/database/introducing-the-aurora-storage-engine/
l https://www.percona.com/blog/2016/05/26/aws-aurora-benchmarking-part-2/
2022-03-19 / Sungwook Kang / http://sungwookkang.com
AWS RDS, MySQL, AWS Aurora, RDS Aurora, MySQL Aurora, Aurora Storage, Storage Node
'AWS' 카테고리의 다른 글
| [AWS RDS] Modify RDS instance type (0) | 2022.03.23 |
|---|---|
| [AWS RDS] Modify RDS SQL Server Standard Edition to Enterprise Edition (0) | 2022.03.22 |
| [AWS Aurora] Aurora I/O Planning (0) | 2022.03.20 |
| [AWS RDS MySQL] RDS MySQL와 Aurora MySQL 차이점 (0) | 2022.03.18 |
| [AWS RDS MySQL] InnoDB cache warming (0) | 2022.03.17 |