MapReduce JobTracker
· Version : Hadoop 3.0.0-cdh6.3.2
하둡 V1의 작업 단위는 잡(Job)이며, 하둡 V2의 작업 단위는 애플리케이션(Application)이다. 잡은 맵(Mapper) 태스크와 리듀스(Reduce) 태크스로 나누어지며, 태스크는 어템프트(Attempt) 단위로 실행된다. 맵리듀스 Job들은 JobTracker라는 소프트웨어 데몬의 의해 제어된다. JobTracker들은 마스터 노드에 존재하면서 아래와 같은 역할을 수행한다.
· 클라이언트는 맵리듀스 잡을 JobTracker에게 보낸다.
· JobTracker는 클러스터의 다른 노드들에게 맵과 리듀스 태스크를 할당한다.
· 이 노드들은 TaskTracker라는 소프트웨어 데몬에 의해 각각 실행된다.
· TaskTracker는 실제로 맵 또는 리듀스 태스크를 인스턴트화하고, 진행 상황을 Job Tracker에게 보고할 책임이 있다.

Task Attempt는 태스크를 실행하기 위한 특정 인스턴스를 의미하는데, 적어도 하나 이상의 태스크가 존재하기 때문에 많은 Task attempt가 있을것이다. 만약 Task attempt가 실패하면, JobTracker에서 설정된 횟수만큼 Task attempt를 실행한다. 반복후에도 오류가 발생하면 작업을 종료한다.
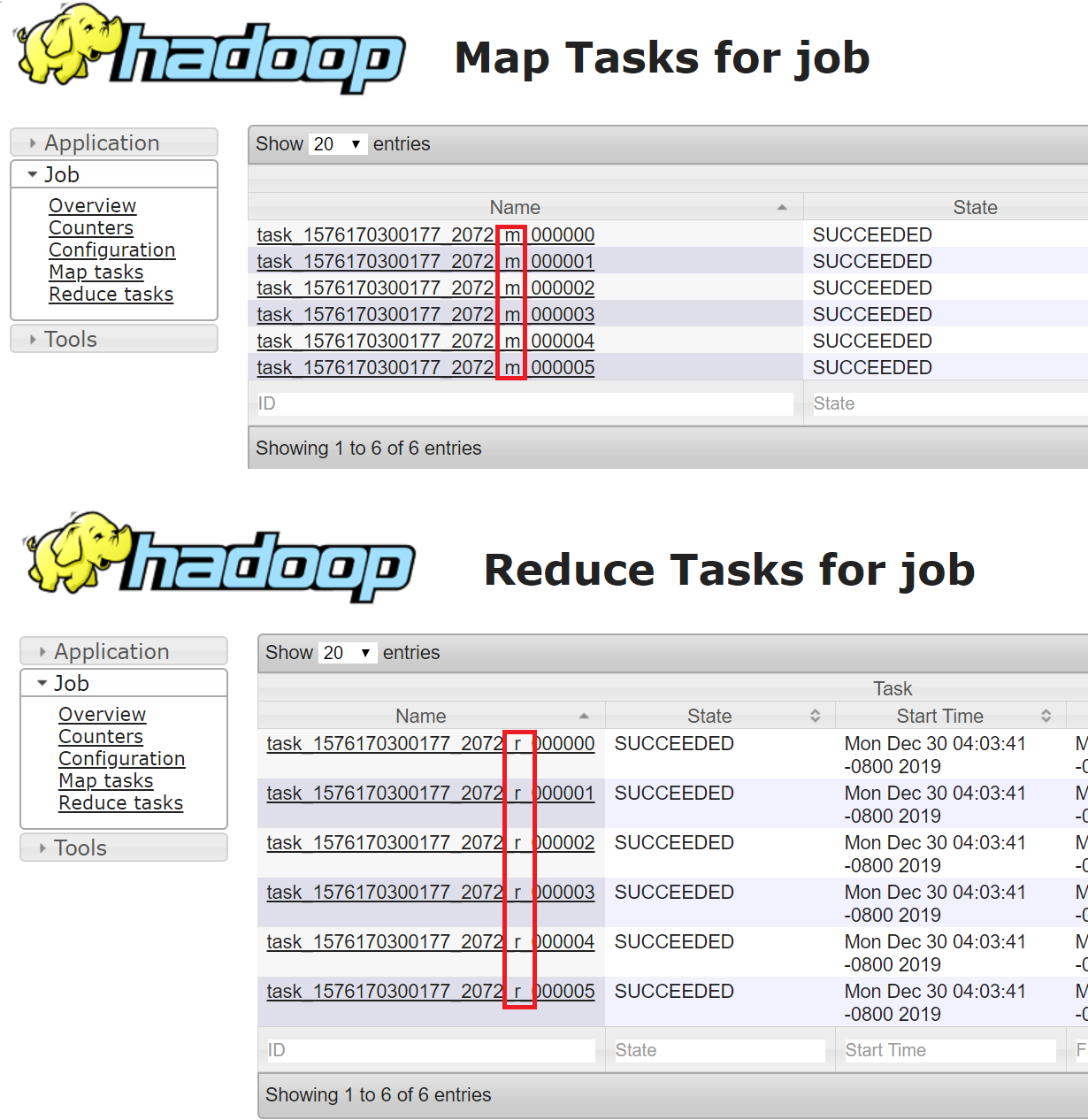
하둡 잡이 실행되면 아이디가 job_xxx_xxx로 생성된다. 이 아이디로 잡의 상태, 로그를 확인할 수 있다. YARN에서는 application_xxx_xxx로 확인할 수 있다. Job에서 생성되는 맵태스크의 아이디는 attempt_xxx_xxx_m_000000_00 이며,리듀스태스크의 아이디는 attempt_xxx_xxx_r_000000_00으로 생성된다.중간 아이디로 맵 태스크(m)와 리듀스 태스크(r)로 구분한다.
2019-12-30 / Sungwook Kang / http://sungwookkang.com
Hadoop, MapReduce, JobTracker,맵 태스크, 리듀스 태스크, 잡트래커, JobTracker in Hadoop
'SW Engineering > Hadoop' 카테고리의 다른 글
| MapReduce 메모리 설정 (0) | 2020.01.07 |
|---|---|
| Hive에서 콤마(,)로 컬럼 구분 및 쿼테이션 내부의 콤마(“, , ”) 파싱 스킵하기 (0) | 2020.01.03 |
| MapReduce (맵리듀스) (0) | 2019.12.28 |
| Hive Buckets (버켓) (0) | 2019.12.27 |
| Hive Skewed (스큐) (0) | 2019.12.24 |