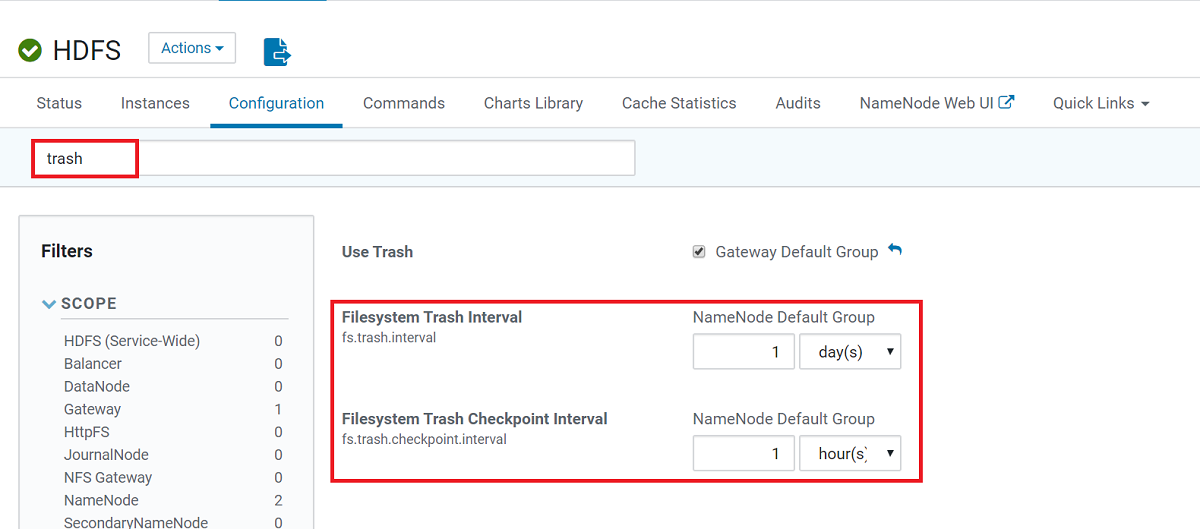
HDFS에서 파일 삭제시 바로 삭제 될까? (휴지통 기능) · Version : Hadoop 3.0.0-cdh6.3.2 HDFS에서 파일 삭제시 즉시 삭제되고 빈 공간이 반환될까? HDFS에는 휴지통 기능이라는 것이 있어서, 파일 삭제시 즉시 삭제되지 않고 휴지통 폴더 (/user/사용자명/.trash)로 이동된다. 휴지통에 있는 파일은 복구 할 수 있다. 휴지통 디렉터리는 설정된 간격으로 체크포인트가 실행되고, 설정된 기간이 지나면 영구 삭제 된다. 영구 삭제가 완료되면 유휴 공간으로 반환된다. 휴지통의 삭제 기간은 core-site.xml 파일에서 설정할 수 있다. fs.trash.interval 1440 fs.trash.checkpoint.interval 120 · fs.trash.interval ..