MySQL HA 환경에서 Orchestrator를 활용한 클러스터 리팩토링 및 자동 장애조치 구성
l Version : MySQL, Orchestrator
MySQL HA 환경에서 Orchestrator(이하 ‘오케스트레이터’)를 활용하여 클러스터 리팩토링 및 장애조치 방법에 대해서 알아본다. 이번 실습을 진행하기 위해서는 MySQL HA 및 Orchestrator 구성이 완료되어 있어야 한다. 아래 링크를 참고하여 HA구성 및 Orchestrator를 구성할 수 있도록 한다.
l ProxySQL 설치 (MySQL 설치부터, 복제 구성, ProxySQL 설정까지 한번에) : https://sungwookkang.com/1529
l MySQL 고가용성 운영을 위한 Orchestrator 설치 : https://sungwookkang.com/1532
실습에 사용되는 서버 구성이다.
| Server Name | IP | OS | Service Version |
| proxy-sql | 172.30.1.49 | Ubuntu 22.04.2 LTS | ProxySQL version 2.4.2-0-g70336d4, codename Truls |
| mysql-master | 172.30.1.97 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33 |
| mysql-slave1 | 172.30.1.10 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33 |
| mysql-slave2 | 172.30.1.13 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33 |
| proxy-orchestrator | 172.30.1.24 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33, container.d |
MySQL HA 기본 구성으로 1대의 마스터 서버와, 2대의 슬레이브 서버가 GTID 기반으로 복제 구성이 되어 있다.
이번 포스트에서 4개의 시나리오를 구성해 보았으며, 각 시나리오별로 실습 과정을 다루었다.
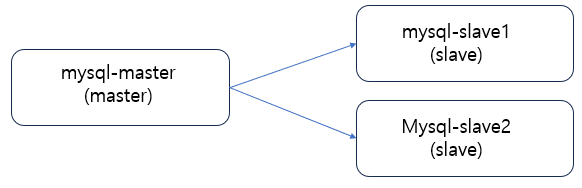
시나리오1. Slave Refactoring
Slave간에 복제 토폴로지 리팩토링으로, 슬레이브1, 슬레이브2가 마스터에서 싱크하던 환경에서, 슬레이브2가 슬레이브1에서 복제를 싱크할 수 있도록 토폴로지를 변경한다.

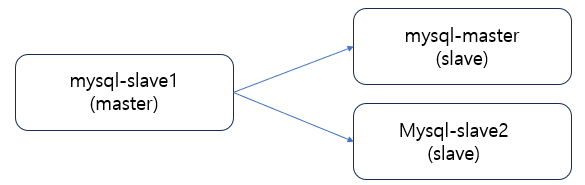
시나리오2. Master Refactoring (Promote)
슬레이브 서버를 마스터로 승격시키고, 기존의 마스터를 슬레이브로 역할을 전환한다.
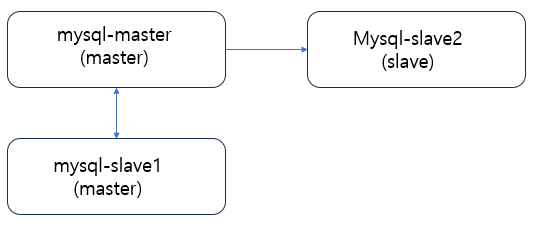
시나리오3. Master – Master Refactoring
슬레이브 서버중 하나를 마스터로 승격시켜 두 대의 마스터로 구성한다.
시나리오4. Master Failover
기존의 운영중이던 마스터 서버를 강제로 중지하여 장애 상황을 구현한 다음, 현재 슬레이브로 운영되던 서버중 하나가 새로운 마스터가 되어 장애조치 된다. 그리고 나머지 슬레이브 서버는 새로운 마스터 서버와 복제 싱크를 한다.

실습환경 살펴보기
오케스트레이터 대시보드에 접속하면 현재 구성되어 있는 클러스터 목록을 볼 수 있다. 여기에서 숫자 3과 1이 보이는데, 3은 현재 구성된 클러스터의 전체 서버 개수이며, 2는 슬레이브 서버 개수이다.

클러스터를 클릭해보면 현구 구성되어 있는 클러스터 토폴로지를 확인할 수 있다. 각 시나리오에 따라 서버의 역할이 변경되기 때문에, 현재 구성되어 있는 서버이름과 역할을 혼돈하지 않도록 주의한다.

시나리오1. Slave Refactoring
Slave간에 복제 토폴로지 리팩토링으로, 슬레이브1, 슬레이브2가 마스터에서 싱크하던 환경에서, 슬레이브2가 슬레이브1에서 복제를 싱크 할 수 있도록 토폴로지를 변경한다.
mysql-slave2(172.30.1.13)서버를 드래그하여 mysql-slave1(172.30.1.10) 서버에 드롭한다. 이때 드롭 할 위치가 중요하다. 서버의 중간쯤으로 이동하면 드롭하는 서버 정보에 relocate라고 표시가 되는데 이때 드롭한다.
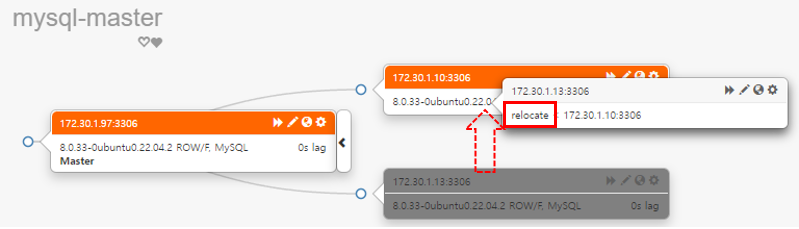
Relocate에 대한 변경 사항에 대해서 경고 팝업이 나타나고 OK를 클릭하면 변경 사항이 적용된다.

클러스터 토폴로지 구조가 변경된 것을 확인할 수 있다.

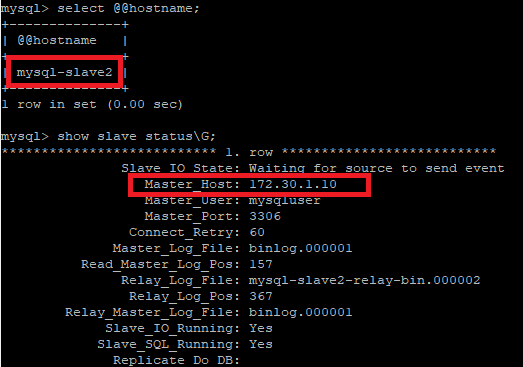
mysql-slave2(172.30.1.13) 서버에 접속하여 호스트 이름 및 복제 상태를 조회해 보면, 현재 mysql-slave1(172.30.1.10) 서버를 마스터 호스트로 연결되어 있는 것을 확인할 수 있다.
| select @@host; show slave status\G; |
시나리오를 처음 상태로 원상복구하려면 mysql-slave2(172.30.1.13)를 드래그하여 mysql-master(172.30.1.97)에 드롭 한다.

Relocate에 대한 변경 사항에 대해서 경고 팝업이 나타나고 OK를 클릭하면 변경 사항이 적용된다.

클러스터 토폴로지 구조가 변경된 것을 확인할 수 있다.

mysql-slave2(172.30.1.13) 서버에 접속하여 호스트 이름 및 복제 상태를 조회해 보면, 현재 mysql-master(172.30.1.97) 서버가 마스터 호스트로 연결되어 있는 것을 확인할 수 있다.

시나리오2. Master Refactoring (Promote)
슬레이브 서버를 마스터로 승격시키고, 기존의 마스터를 슬레이브로 역할을 전환한다.
mysql-slave1(172.30.1.10)을 드래그 하여 mysql-master(172.30.1.97)로 드롭 한다. 이때 드롭하는 위치를 현재 마스터보다 조금 앞으로 위치하여 PROMOTE AS MASTER가 표시될 때 드롭 한다. (마스터 보다 뒤에 할 경우 relocate로 표시된다.)

Takeover에 대한 경고 팝업이 나타나고 OK를 클릭하면 변경 사항이 적용된다.

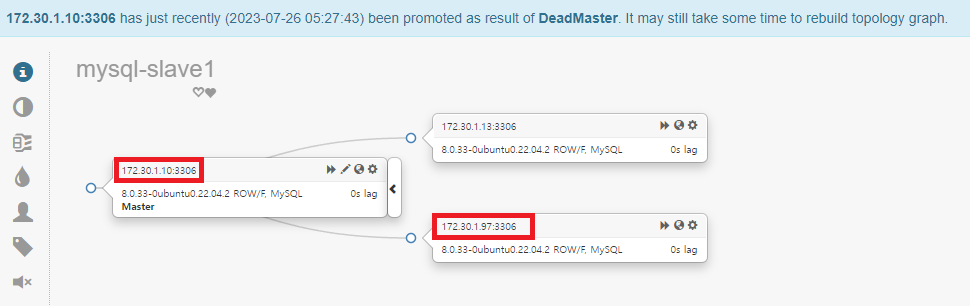
변경사항을 적용하였을 때, 대시보드 화면이 바로 갱신이 안되는 경우가 있다. 이때 새로고침을 하면 변경사항이 정상적으로 나타난다. 현재 구성되어 있는 토폴로지 상태를 보면, mysql-slave1(172.30.1.10) 서버가 master 역할을 하며, mysql-master(172.30.1.97)서버가 slave 역할을 하는 것으로 역할 체인지가 된 것을 확인할 수 있다. 하지만 mysql-master(172.30.1.97) 서버를 보면 역할 변경 후 새로운 마스터에 대한 복제 구성이 되지 않아서 오류로 표시되고 있다.

복제 시작을 위해 slave역할의 mysql-master(172.30.1.97) 서버에서 메뉴 아이콘을 클릭하면 설정 팝업이 나타나는데, [Start replication]을 클릭한다.

복제가 정상적으로 구성되고 모든 클러스터가 정상으로 표시되는 것을 확인할 수 있다.
다음 실습을 준비하기 위해 원래 클러스터 토폴로지 구조로 원상복구를 한다. 원상복구 방법은 앞에서 했던 방법과 동일하게 진행한다.
시나리오3. Master – Master Refactoring
슬레이브 서버중 하나를 마스터로 승격시켜, 두 대의 마스터로 구성한다.
mysql-master(172.30.1.97) 서버를 드래그 하여 mysql-slave1(172.30.1.10)에 드롭 한다. 이때 MAKE CO MASTER가 표시되면 드롭 한다.
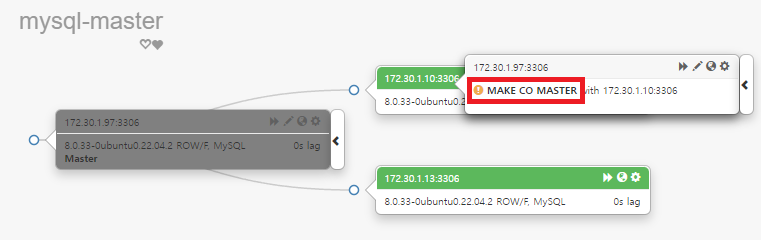
make-co-master에 대한 경고 팝업이 나타나고 OK를 클릭하면 변경 사항이 적용된다.

실행이 완료되면 클러스터 토폴로지 구성이 master – master 로 변경된 것을 확인할 수 있다.

정확히는 master-master 구조만 만들어진 상황으로, 완벽한 master-master 작동을 하는 것은 아니다. 환경은 구성되었지만 mysql-slave(172.30.1.10) 서버는 현재 Read Only 상태이다. [Set writeable]를 클릭하여 쓰기 상태로 변경해야 사용가능한 master-master 환경이 된다.
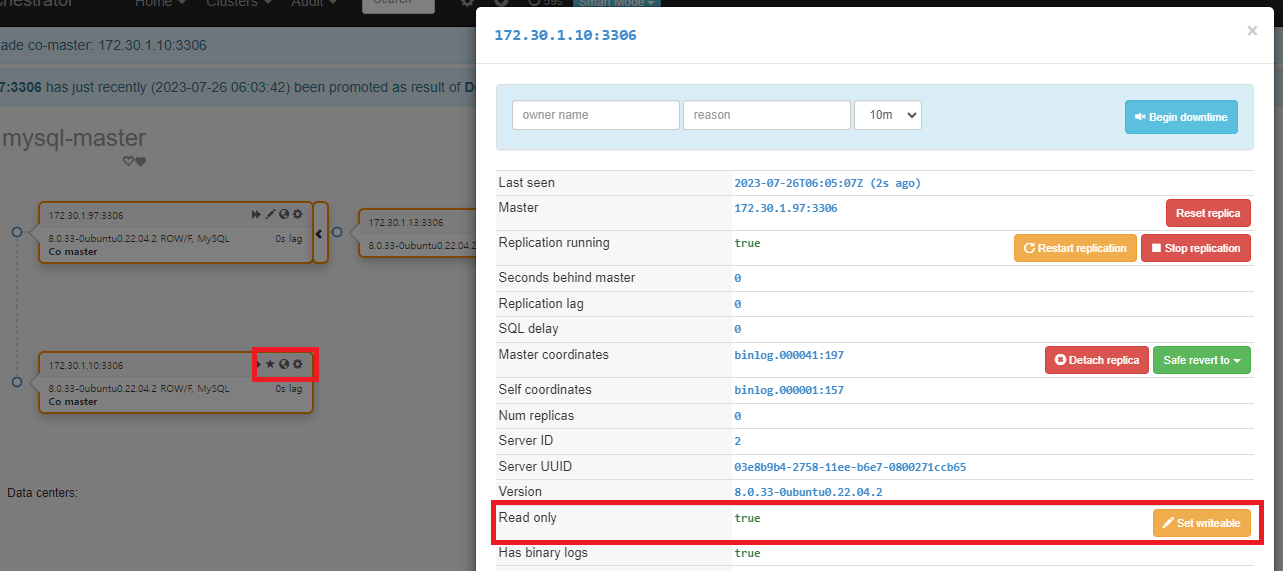
master-master 구조에서 master-salve로 원복하기 위해서는 mysql-master(172.30.1.97) 서버에서 설정 아이콘을 클릭한다. 팝업이 나타나면 Master 항목에서 [Reset replica]를 클릭한다.

이전과 같은 상태로 클러스터 토폴로지가 구성된 것을 확인할 수 있다.

시나리오4. Master Failover
기존의 운영중이던 마스터 서버를 강제로 중지하여 장애 상황을 구현한 다음, 현재 슬레이브로 운영되던 서버중 하나가 새로운 마스터가 되어 장애조치 된다. 그리고 나머지 슬레이브 서버는 새로운 마스터 서버와 복제 싱크를 한다.
현재 master역할을 하고 있는 mysql-master(172.30.1.97) 서버에 접속하여 MySQL 서비스를 강제로 중지한다.
| hostname sudo systemctl stop mysql |

MySQL 서비스가 중지되고 오케스트레이터가 장애 상황을 인지하면 아래와 같이 대시보드 상태가 변경된다. 파란색 숫자3은 현재 구성되어 있는 클러스터 서버 개수이며, 빨간색 숫자2는 슬레이브 개수이며 복제 불가능을 표시하고 있다. 검은색 1은 응답 없는 서버 개수를 나타낸다.

해당 클러스터를 클릭해서 상세 대시보드를 살펴보면, 현재 mysql-master(172.30.1.97) 서버가 응답 없음을 나타내고 있으며, 슬레이브는 복제가 되지 않는 것을 확인할 수 있다. 우측의 느낌표를 클릭하면 각 노드의 에러 메시지를 상세하게 확인할 수 있다.
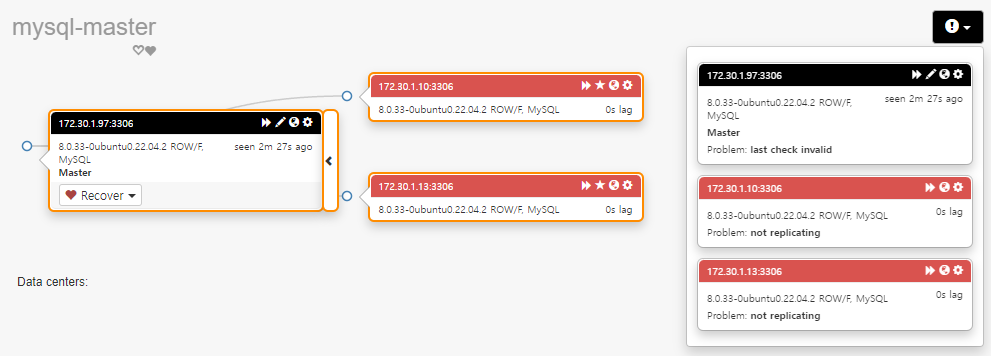
오류 메시지는 오케스트레이터의 로그 파일에서도 확인할 수 있다. 특별히 경로를 변경하지 않았으면 아래 경로에서 확인 가능하다. 만약 경로 확인이 필요하면 설정 파일에서 확인할 수 있다.
| /tmp/recovery.log |
[수동 Failover]
오케스트레이터의 장애조치 모드 기본값은 수동이다. 수동으로 장애조치는 관리자가 문제를 인지하고 직접 장애 조치를 진행해야 한다. 현재 응답이 없는 mysql-master(172.30.1.97) 서버에서 [Recover]를 클릭한다. Failover 가능한 서버 목록에서, mysql-salve1(172.30.1.10)서버로 장애조치를 진행한다.

장애조치를 실행하게 되면, 응답 없는 서버를 기존의 클러스터에 분리된다. 기존 서비스가 중지된 mysql-master 노드는 기존 클러스터에서 분리된 것을 확인할 수 있다.

클러스터를 클릭하여 상세 내용을 보면 mysql-slave1(172.30.1.10) 서버가 master역할을 하고, mysql-slave2(172.30.1.13) 서버가 slave역할을 하는 것을 확인할 수 있다.

mysql-master(172.30.1.97) 서버를 복구했다는 가정하에 mysql-master(172.30.1.97) 서비스를 다시 시작한다.

MySQL 서버가 정상적으로 실행되었으며 현재는 독립적으로 실행되고 있기 때문에, 기존의 복제 클러스터에 조인하기 위해서는 현재 master 역할로 운영중인 mysql-slave1(172.30.1.10) 서버로 복제를 연결한다.
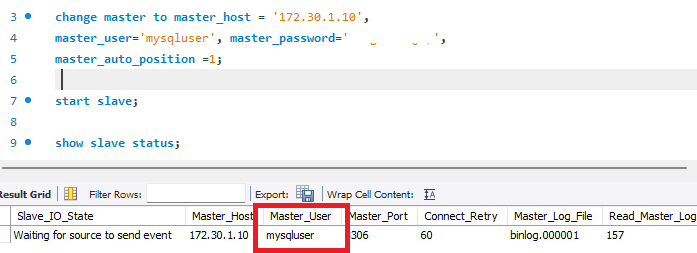
복제가 성공적으로 연결되고, 복제 싱크가 완료되면 오케스트레이터 대시보드에서도 클러스터가 정상적으로 연결되어 운영되는 것을 확인할 수 있다.
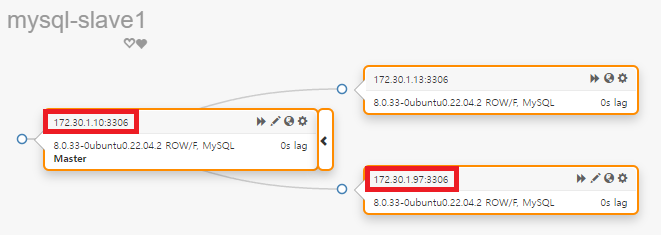
[자동 failover]
기본 모드가 수종이기 때문에, 자동으로 장애조치를 하기 위해서는 파라메터 수정이 필요하다. 아래 경로의 설정파일에서 수정할 수 있다. 설정 파라메터의 종류가 많기 때문에 주의해서 살펴본다.
| vi /usr/local/orchestrator/orchestrator.conf.json |

| 변경전 | 변경후 |
| "RecoveryPeriodBlockSeconds": 3600, "RecoveryIgnoreHostnameFilters": [], "RecoverMasterClusterFilters": [ "_master_pattern_" ], "RecoverIntermediateMasterClusterFilters": [ "_intermediate_master_pattern_" ], |
"RecoveryPeriodBlockSeconds": 10, "RecoveryIgnoreHostnameFilters": [], "RecoverMasterClusterFilters": [ "*" ], "RecoverIntermediateMasterClusterFilters": [ "*" ], |
설정 변경을 완료하였으면, 오케스트레이터는 설정 파일에 대한 변경사항을 런타임중에 적용할 수 있다. 대시보드 상단 메뉴에서 [Home] - [Status]를 클릭한다. Status페이지에서 [Reload congifuration]을 클릭하여 설정을 로드 한다.

자동 장애조치 테스트를 위해 현재 master로 운영중인 서버의 MySQL을 강제로 중지한다.

Master서버가 중지되고 오케스트레이터에서 장애 상황을 인지한 다음 자동으로 장애조치가 완료되면 대시보드에서 아래와 같이 두 개의 클러스터를 볼 수 있다. 장애가 발생한 서버는 기존 클러스터에서 분리가 되었다.

각 클러스터를 클릭해서 상태를 살펴보면, 기존의 slave 서버중에 하나가 master로 승격되고, 나머지 슬레이브가 새로운 마스터에 조인되어 싱크되는 것을 확인할 수 있다.
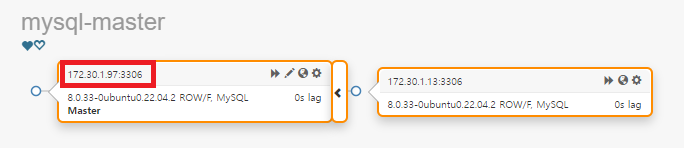
분리된 장애 서버에서는 Recover를 클릭해도 클러스터에서 분리된 상태이기 때문에 failover할 수 있는 서버 목록을 찾을 수 없다고 표시된다.

지금까지 MySQL HA환경에서 오케스터레이터를 활용하여 토포로지 리팩토링 및 장애조치 하는 방법에 대해서 살펴보았다. 장애조치를 진행할 때 운영중인 서버중 하나가 랜덤하게(정확히는 씽크가 가장 빠른 서버) 마스터로 승격되는 것을 확인하였는데, 이 또한 파라메터를 수정하여 다양한 조건을 부여하여 우선순위조건을 조정할 수 있다. 앞애서도 살펴보았듯이 파라메터의 종류가 매우 많다. 상세한 내용은 다른 포스트에서 하나씩 살펴볼 예정이다.
[참고자료]
l Orchestrator : https://github.com/openark/orchestrator
l Failure detection : https://github.com/openark/orchestrator/blob/master/docs/failure-detection.md
l MySQL Orchestrator - HA(High Availability) - 2 - 리팩토링 Failover Automated Recovery : https://hoing.io/archives/91
l Configuration: failure detection : https://github.com/openark/orchestrator/blob/master/docs/configuration-failure-detection.md
l https://code.openark.org/blog/mysql/what-makes-a-mysql-server-failurerecovery-case : https://code.openark.org/blog/mysql/what-makes-a-mysql-server-failurerecovery-case
l Orchestrator: MySQL Replication Topology Manager : https://www.percona.com/blog/orchestrator-mysql-replication-topology-manager/
l Orchestrator and ProxySQL : https://www.percona.com/blog/orchestrator-and-proxysql/
2023-07-27 / Sungwook Kang / http://sungwookkang.com
MySQL, ProxySQL, MySQL Replication, MySQL HA, MySQL복제 오케스트레이션, MySQL복제설치, MySQL MHA, MySQL Orchestrator, MySQL장애조치, MySQL고가용성
'MySQL, MariaDB' 카테고리의 다른 글
| ProxySQL 은 서비스에 필요한 설정값을 어디에 저장하고 재사용할까? (0) | 2023.08.04 |
|---|---|
| MySQL HA + ProxySQL 환경에서 서비스 장애조치 구성 (0) | 2023.08.03 |
| MySQL 고가용성 운영을 위한 Orchestrator 설치 (0) | 2023.07.25 |
| ProxySQL Internals 및 시스템 구성 둘러보기 (0) | 2023.07.24 |
| ProxySQL 쿼리룰 설정으로 Read, Write 부하 분산하기 (0) | 2023.07.23 |