MySQL HA + ProxySQL 환경에서 서비스 장애조치 구성
l Version : MySQL, ProxySQL
MySQL HA + ProxySQL 환경에서 장애조치가 어떻게 동작하는지 알아본다. 실습 환경은 아래 포스트를 참고하여 구성할 수 있도록 한다.
l ProxySQL 설치 (MySQL 설치부터, 복제 구성, ProxySQL 설정까지 한번에) : https://sungwookkang.com/1529
l MySQL HA 환경에서 Orchestrator를 활용한 클러스터 리팩토링 및 자동 장애조치 구성 : https://sungwookkang.com/1533
실습에 사용되는 서버 구성이다.
| Server Name | IP | OS | Service Version |
| proxy-sql | 172.30.1.49 | Ubuntu 22.04.2 LTS | ProxySQL version 2.4.2-0-g70336d4, codename Truls |
| mysql-master | 172.30.1.97 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33 |
| mysql-slave1 | 172.30.1.10 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33 |
| mysql-slave2 | 172.30.1.13 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33 |
| proxy-orchestrator | 172.30.1.24 | Ubuntu 22.04.2 LTS | mysql Ver 8.0.33, container.d |
MySQL HA 기본 구성으로 1대의 마스터 서버와, 2대의 슬레이브 서버가 GTID 기반으로 복제 구성이 되어 있다. 그리고 서버 장애시 역할 변경을 위해 오케스트레이터로 자동 failover를 구성해 놓은 상태이다.

ProxySQL에서는 각 노드의 서비스 상태를 헬스 체크하여 서비스에 사용할 서버를 판단한다. 아래는 노드의 서비스 상태를 체크하는 모듈이다.
l connect : 모든 노드(백엔드)에 연결하고 성공 또는 실패를 mysql_server_connect_log 테이블에 기록한다.
l ping : 모든 노드 (백엔드)에 ping을 보내고 성공 또는 실패를 mysql_server_ping_log 테이블에 기록한다. mysql-monitor_ping_max_failures에 하트비트가 없으면 MySQL_Hostgroups_Manager에 신호를 보내 모든 연결을 끊는다.
l replication lag : max_replication_lag가 0보다 큰 값으로 구성된 모든 노드(백엔드)에 대해 Seconds_Behind_Master를 확인하고 mysql_server_replication_lag_log 테이블에 확인을 기록한다. Seconds_Behind_Master > max_replication_lag인 경우 Seconds_Behind_Master < max_replication_lag까지 서버를 회피한다.
l read only : mysql_replication_hostgroup 테이블의 호스트 그룹에 있는 모든 호스트에 대해 읽기 전용을 확인하고, 상태값은 mysql_server_read_only_log에 기록된다. read_only=1이면 호스트가 reader_hostgroup으로 복사/이동되고, read_only=0이면 호스트가 writer_hostgroup으로 복사/이동된다.
이번 포스트에서 다루는 ProxySQL 장애조치 시나리오는 두 가지이다.
l 시나리오 1 : slave 서버에 장애가 발생하여 장애가 발생한 서버로는 read 트래픽을 요청하지 않는다.
l 시나리오2 : master 서버에 장애가 발생하여 slave 서버중 하나가 master로 승격되고, ProxySQL의 호스트 그룹에서 Write가 가능한 호스트 그룹을 변경한다.
시나리오에 따른 실습을 하기 전에 현재 구성되어 있는 ProxySQL에 접속하여 현재의 상태를 살펴본다. proxy-sql 서버에서 아래와 같은 스크립트를 실행하여, ProxySQL 관리 모드로 접속한다.
| mysql -uadmin -padmin -h 127.0.0.1 -P6032 --prompt='admin> ' |
현재 호스트 그룹에 등록된 서버들의 목록을 확인할 수 있다. hostgroup_id = 1 은 write가 가능한 그룹이며, hostgroup_id = 2는 읽기가 가능한 그룹이다.
| select * from mysql_servers; |

아래 스크립트는 등록된 서버들의 커넥션 로그를 확인한다. 만약 여기서 커넥션 오류로그가 있다면 해당 서버와의 통신에 문제가 발생한 것이다.
| select * FROM monitor.mysql_server_connect_log order by time_start_us desc limit 10; |

위의 커넥션 로그가 실제 쿼리가 호출될 때 확인된다면, 아래는 서비스 헬스 체크를 위한 핑 로그이다.
| select * from monitor.mysql_server_ping_log order by time_start_us desc limit 10; |
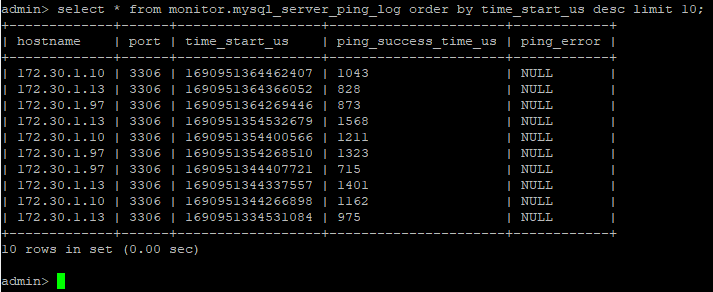
ProxySQL의 클라이언트용 포트로 접속하여 현재 상태에서 정상적으로 모든 서버가 응답하는지 테스트한다.
| mysql -uubuntu -p123456 -h127.0.0.1 -P6033 -e "SELECT @@hostname"; |

아래 스크립트에서는 현재 연결된 커넥션 풀에 대한 상태를 확인할 수 있다. 실제 연결에 문제가 발생할 경우 stats_mysql_connection_pool의 status 컬럼에 상태가 변경되는 것을 확인할 수 있다.
| select * from stats_mysql_connection_pool; |

시나리오1. slave 서비스 장애
slave 서버중 하나에 장애가 발생한 상황으로, 장애가 발생한 서버로는 읽기 요청을 하지 않도록 하여 서비스 장애를 예방한다.
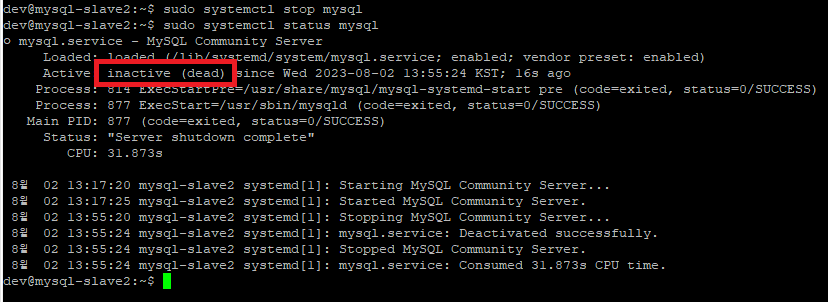
mysql-slave2 서버에 접속하여, MySQL 서비스를 중지한다.
| sudo systemctl stop mysql sudo systemctl status mysql |
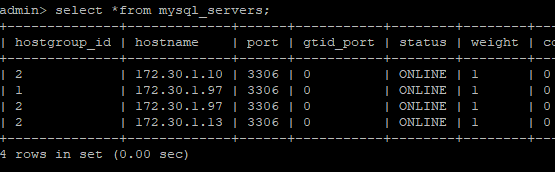
서비스가 종료된 상태에서 ProxySQL 관리자의 mysql_servers 테이블 상태를 살펴보면 여전히 모든 서버가 ONLINE 상태로 보이는 것을 확인할 수 있다. 사실 이 테이블은 서버의 목록을 관리하는 것이지, 서버의 상태를 나타내지는 않는다. 다만 수동으로 status 값을 OFFLINE으로 변경하면, 서비스가 활성화 상태여도 해당 서버로 트래픽을 보내지 않는다.
| select * from mysql_servers; |
현재 실시간의 노드의 상태를 확인하려면 runtime_mysql_servers 테이블의 정보를 확인한다. 아래 스크립트를 사용하여 중지된 서버의 상태가 SHUNNED로 표시된 것을 확인할 수 있다.
| select * from runtime_mysql_servers; |

커넥션 풀 상태에서도 동일하게 SHUNNED으로 나타나는 것을 확인할 수 있다.
| select * from stats_mysql_connection_pool; |

커넥션 로그를 확인해보면 중지된 서버(mysql-slave2)의 커넥션 실패 로그를 확인할 수 있다.
| select * FROM monitor.mysql_server_connect_log order by time_start_us desc limit 10; |
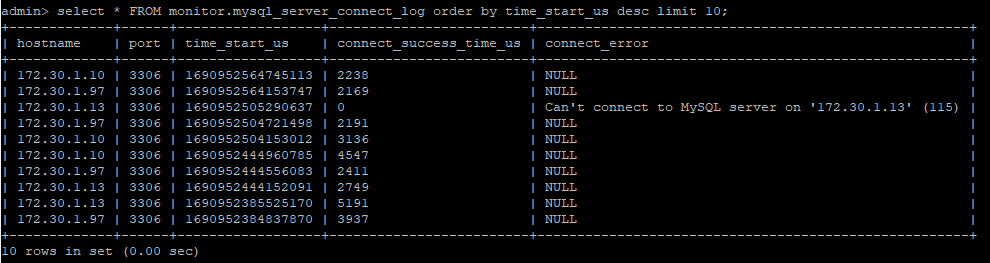
핑 로그에서도 오류를 확인할 수 있다.
| select * from monitor.mysql_server_ping_log order by time_start_us desc limit 10; |

mysql-slave2 서버의 MySQL 서비스가 중지된 상태로, ProxySQL에서도 해당 서버의 문제점을 인지한 상태이다. 이제 클라이언트 연결을 통해서 실제 운영중인 서버로만 트래픽이 정상적으로 라우팅 되는지 확인한다. 테스트를 위해 proxy-sql 서버 콘솔에서 아래 스크립트를 여러 번 실행한다.
| mysql -uubuntu -p123456 -h127.0.0.1 -P6033 -e "SELECT @@hostname"; |
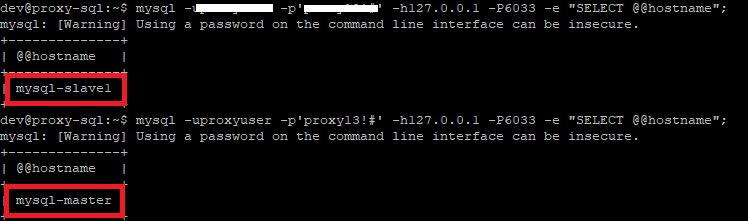
문제의 서버를 제외하고 정상적인 서버로만 트래픽을 라우팅하는 것을 확인할 수 있다. ProxySQL에서는 이렇게 문제의 서버를 감지하여 트래픽을 보내지 않음으로써 서비스 장애를 예방할 수 있다.
다른 시나리오 테스트를 진행하기 위해 중지된 서버를 시작하여 클러스터를 원상 복구한다.
시나리오2. master 서버 장애
이번 시나리오는 master서버에 장애가 발생하여, 서비스가 다운되고, slave 서버 중 하나가 master로 승격되어 운영되는 환경이다. 이때 장애를 감지하고 자동으로 서버를 승격시키는 역할은 MySQL 오케스트레이터가 한다.
mysql-master 서버에 접속하여 MySQL 서비스를 중지한다. 오케스트레이터에서는 master 서버의 장애를 감지하고, 중지된 master 서버를 클러스터에서 격리한 후 slave 서버중 하나를 master로 승격여 클러스터 토폴로지를 재구성한다.

새로 구성된 클러스터를 살펴보면 이전 slave역할이었던 mysql-slave2(172.30.1.13)서버가 master로 승격된 것을 확인할 수 있다. 그리고 나머지 slave 서버가 새로운 master를 복제하고 있다.

ProxySQL에서도 커넥션 풀 로그를 확인해보면 기존의 master역할을 하던 mysql-master(172.30.1.97)에 문제가 있음을 인지한 것을 확인할 수 있다.
| select * from stats_mysql_connection_pool; |

실행중인 서버의 상태를 확인해봐도 문제를 인지한 것을 확인할 수 있다.
| select * from runtime_mysql_servers; |
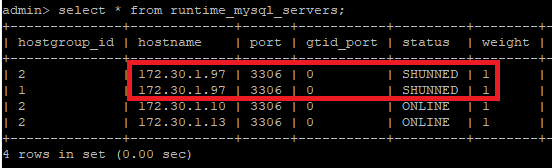
proxy-sql에서 문제가 발생한 노드가 제외되고 서비스가 정상적으로 되는지 확인한다. 호스트 이름을 검색하는 쿼리를 실행해보면 문제없이 잘 작동한다
| mysql -uubuntu -p123456 -h127.0.0.1 -P6033 -e "SELECT @@hostname"; |

하지만 현재 상태는 정상적인 서비스를 할 수 없는 큰 문제가 있다. 현재 클러스터 상태는 기존의 mysql-master (마스터 역할) 서버가 중지되고 mysql-slave2서버가 master 역할로 승격된 상태인데, mysql_servers 테이블의 정보에는 여전히 이전의 mysql-master 서버가 hostgroup_id=1에 등록되어 있다. 실질적으로 ProxySQL에서는 Write가 가능한 서버를 잘못 인식하고 있는 상태이다. 이 정보를 업데이트하지 않으면 write에 대해서는 계속해서 실패가 발생하게 된다.
이러한 서버 장애시 hostgroup_id를 자동으로 변경하기 위해 복제 호스트 그룹으로 관리할 수 있다. 단, 이렇게 하기 위해서는 역할에 따른 MySQL 서버의 Read only 속성값이 중요하다. master 역할 서버는 read_only =false로, slave 역할의 서버는 read_only=true 로 되어 있어야 한다. 그렇지 않으면 ProxySQL에서는 read_only=false 서버를 write가 가능한 서버로 인식하기 때문에 master-master구조로 인식되어 의도하지 않는 write 오류가 발생할 수 있다.

아래 스크립트는 write가 가능한 호스트들은 1 그룹으로, 읽기가 가능한 호스트들은 2 그룹으로 할당한다. 서버의 정보를 변경하였기에 해당 변경 사항이 런타임으로 적용될 수 있도록 LOAD 명령어도 함께 실행한다.
| INSERT INTO mysql_replication_hostgroups VALUES (1,2,'read_only','1=write, 2=read'); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; |

기존의 클러스터 구성으로 원상 복구하고, mysql-master (마스터 역할) 서버를 중지하였을 때, 오케스트레이터에서 자동 장애 조치가 활성화되어 서비스가 중지된 master 서버는 클러스터에서 분리하고, 정상적인 slave 서버중 하나를 master로 승격한다. 그리고 ProxySQL에서는 slave에서 master로 승격된 서버를 houstgroup_id=1로 자동 할당되는 것을 확인할 수 있다.
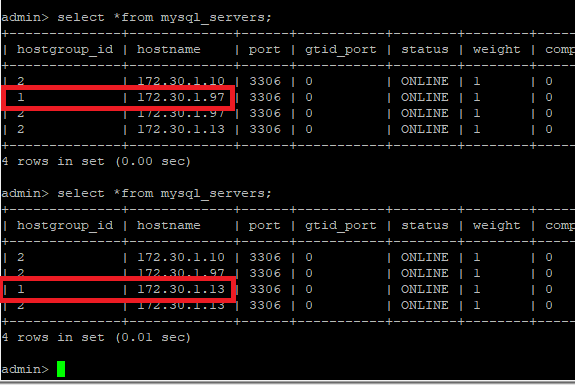
런타임 서버 상태 테이블에서도 장애가 발생한 서버는 SHUNNED로 변경되어 서비스에서 제외된 것을 확인할 수 있으며, 새로운 master 서버가 hostgroup_id=1 변경된 것을 확인할 수 있다.

이번 실습을 통해서 mysql_servers의 테이블은 호스트의 상태 값을 관리하는 테이블이 아닌 호스트 그룹을 관리하기 위한 서버 목록 용도로 사용되는 것을 알 수 있었으며, 실제 서비스들의 상태나 운영가능한 호스트들이 목록은 runtime_mysql_servers 테이블에서 확인 가능한 것을 알 수 있었다.
MySQL 오케스트레이터와 ProxySQL을 조합하여 사용할 경우, 오케스트레이터에서는 자동으로 장애를 감지하고 클러스터 토폴로지 재구성으로 빠르게 역할을 승격하여 안정적인 서비스를 유지할 수 있고, ProxySQL에서는 오케스트레이션에서 승격시킨 서버의 상태를 확인하여 호스트 그룹의 정보를 자동으로 변경함으로써, 만약의 상태에도 안정적인 서비스가 가능한 구성을 만들 수 있다는 것을 확인할 수 있다.
[참고자료]
l Orchestrator : https://github.com/openark/orchestrator
l Failure detection : https://github.com/openark/orchestrator/blob/master/docs/failure-detection.md
l MySQL Orchestrator - HA(High Availability) - 2 - 리팩토링 Failover Automated Recovery : https://hoing.io/archives/91
l Configuration: failure detection : https://github.com/openark/orchestrator/blob/master/docs/configuration-failure-detection.md
l https://code.openark.org/blog/mysql/what-makes-a-mysql-server-failurerecovery-case : https://code.openark.org/blog/mysql/what-makes-a-mysql-server-failurerecovery-case
l Orchestrator: MySQL Replication Topology Manager : https://www.percona.com/blog/orchestrator-mysql-replication-topology-manager/
l Orchestrator and ProxySQL : https://www.percona.com/blog/orchestrator-and-proxysql/
2023-08-02 / Sungwook Kang / http://sungwookkang.com
MySQL, ProxySQL, MySQL Replication, MySQL HA, MySQL복제 오케스트레이션, MySQL복제설치, MySQL MHA, MySQL Orchestrator , MySQL장애조치, MySQL고가용성
'MySQL, MariaDB' 카테고리의 다른 글
| MySQL/MariaDB 환경에서 다중 마스터 복제를 지원하는 Galera Cluster 알아보기 (0) | 2023.08.07 |
|---|---|
| ProxySQL 은 서비스에 필요한 설정값을 어디에 저장하고 재사용할까? (0) | 2023.08.04 |
| MySQL HA 환경에서 Orchestrator를 활용한 클러스터 리팩토링 및 자동 장애조치 구성 (0) | 2023.07.27 |
| MySQL 고가용성 운영을 위한 Orchestrator 설치 (0) | 2023.07.25 |
| ProxySQL Internals 및 시스템 구성 둘러보기 (0) | 2023.07.24 |