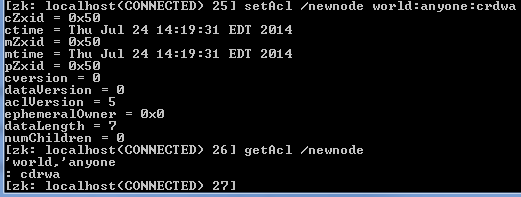
Zookeeper 접근제한(Access Control List) · Version : Zookeeper 주키퍼의 패스와 노드에 대한 권한 관리는 상속되지 않는다. 이 뜻은 부모 노드와 자식 노드가 있을때, 부모의 노드의 권한 속성이 자식 노드로 권한 상속이 발생하지 않다는 것이다. 그리고 아무런 설정을 하지 않으면 누구나 접근이 가능하다. 접근권한은 [schema:id, permission] 같은 형태로 설정한다. Schema는 인증방법을 정의하고, id는 인증을 허용할 값을 정의, permission에는 처리할 수 있는 기능을 정의한다. ex) 특정IP를 가진 클라이언트에 읽기(read) 권한 부여 : ip:192.168.0.1, READ · CREATE : 자식 노드를 생성할 수 있는 권한 · REA..