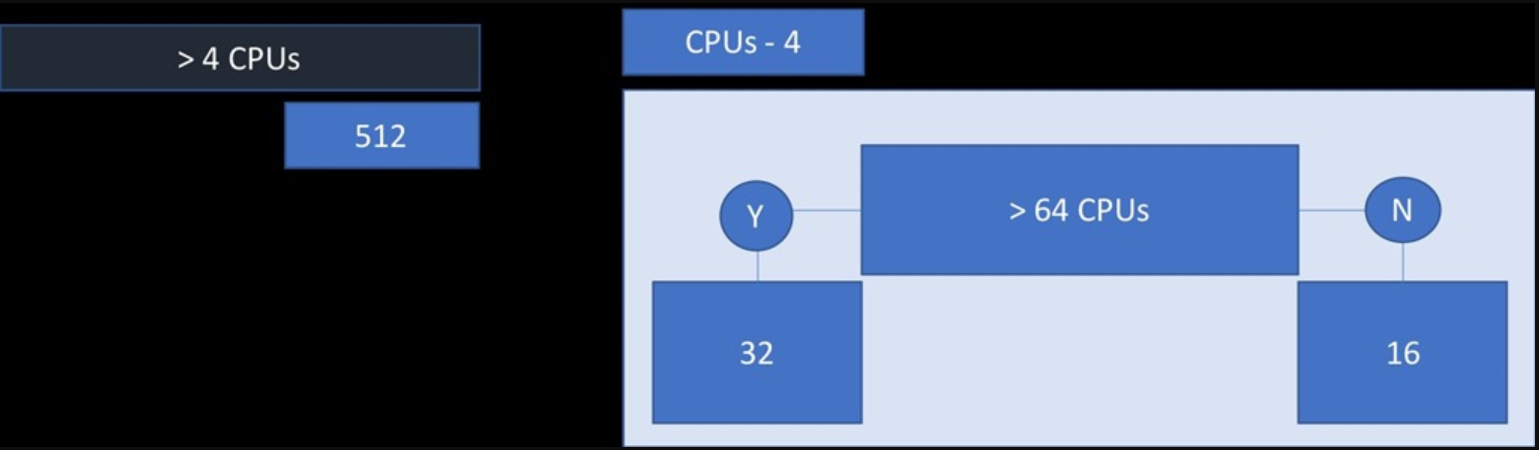
SQL Server 2019 Log Writer Workers · Version : SQL Server 2014, SQL Server 2016, SQL Server 2017, SQL Server 2019 SQL Server 2017은 숨겨진 스케줄러에서 최대 4개의 Log Writer Worker를 활용하여 트랜잭션 로그 처리 활동을 지원한다. SQL Server 2019 버전부터는 하드웨어 성능에 따라 최대 Log Writer Worker 수가 최대 8개까지 증가한다. ;with kgroups AS (SELECT kgroup_count = COUNT(DISTINCT processor_group) FROM sys.dm_os_nodes osn) SELECT SQLServer_version = SERVERP..